
Like everything else in life, stuff can break in your NSX-T environment too. When that happens it’s important to understand how to get things back on track again.
In the following blog articles I’m going through a couple of NSX-T failure scenarios and look at how to recover from them. As usual I’m doing this mainly to learn something myself. By writing about it in a blog article others might learn something as well.
Quick note
Before starting I just want to state the obvious: If you ever experience an issue in your NSX-T production environment, the first and only thing you should do is open a VMware support request. Highly skilled experts who are dealing with all kind of NSX-T issues on a daily basis will help you in the best possible way with your specific issue.
Management plane failure & recovery
As you might know the NSX architecture consists of three main components: The management plane, the control plane, and the data plane. As of NSX-T version 2.4 the management plane and the control plane are living in the same virtual appliance, but from a functional point of view they are still as decoupled as before.
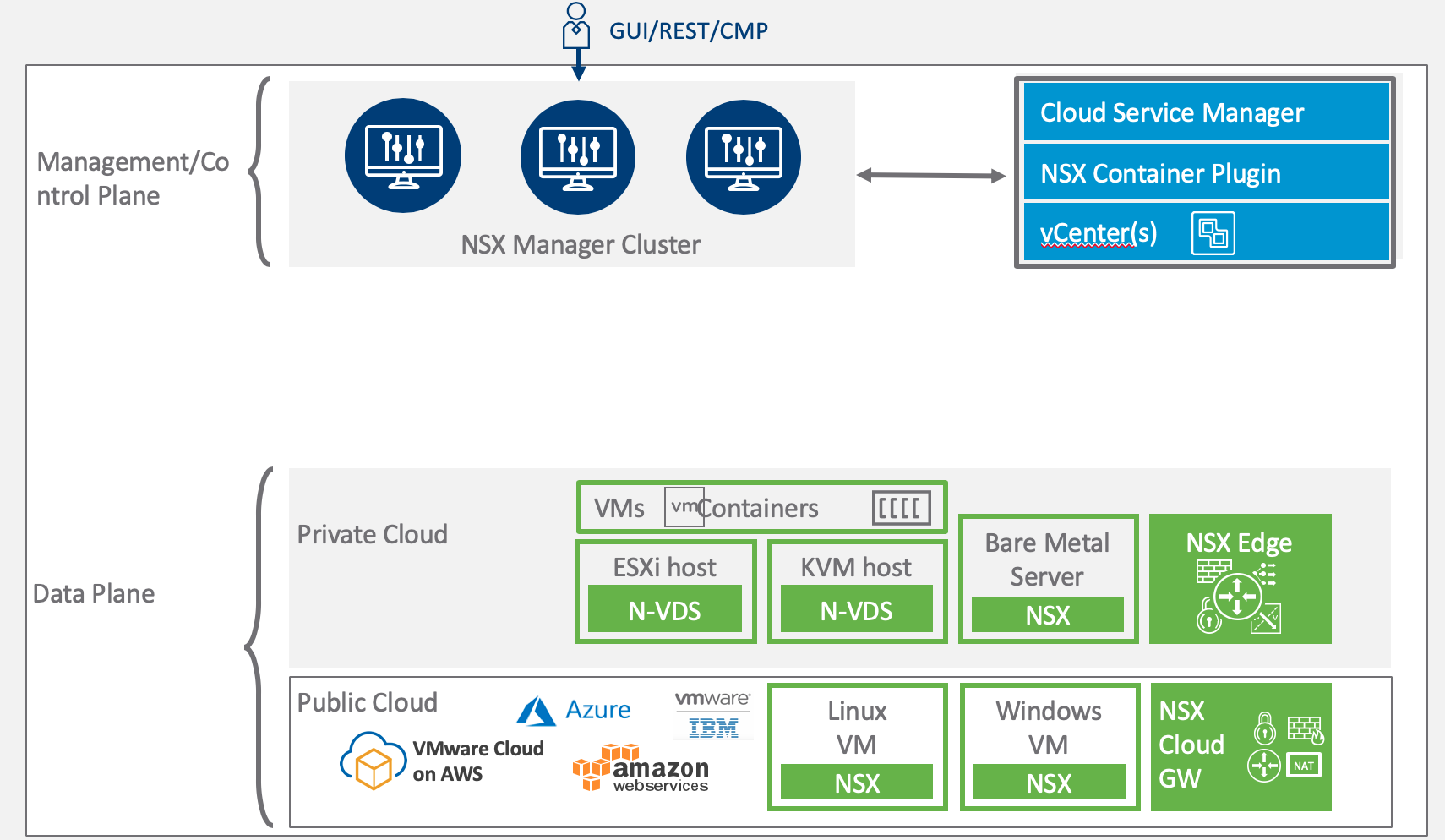
One of the advantages with this architecture is that failure of one plane will not (immediately) affect the functioning of another. For example, a management plane failure won’t cause immediate issues at the data plane.
Of course, NSX-T without a properly functioning management plane gets pretty annoying after a while and restoring it to normal operations will probably be a high priority in most environments. Let’s have a closer look at that.
The lab environment
The following is a very simple and high level overview of my lab environment:
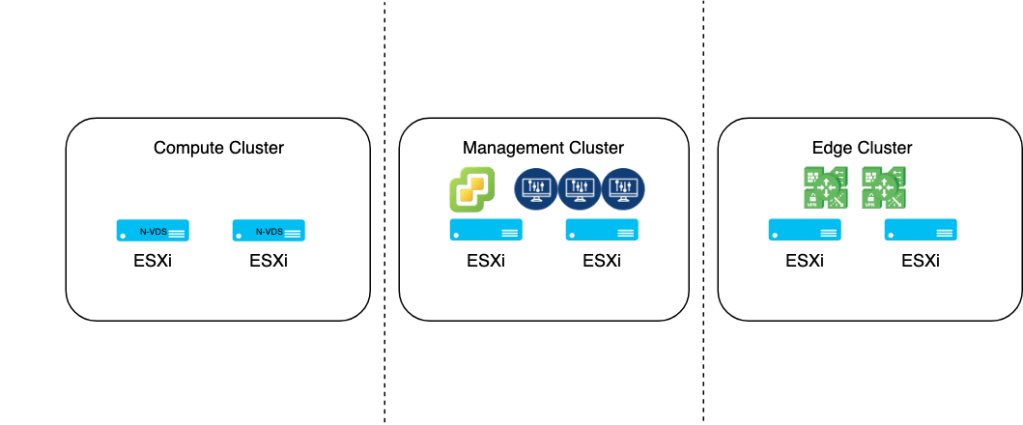
This is by no means a VMware validated or supported design. Just my lab environment.
A compute cluster with two ESXi transport nodes on the left, an edge cluster with two edge VMs on the right, and a management cluster containing vCenter and the collapsed NSX-T management/controller cluster in the middle. Today our focus is the management cluster.
Current state of the management plane
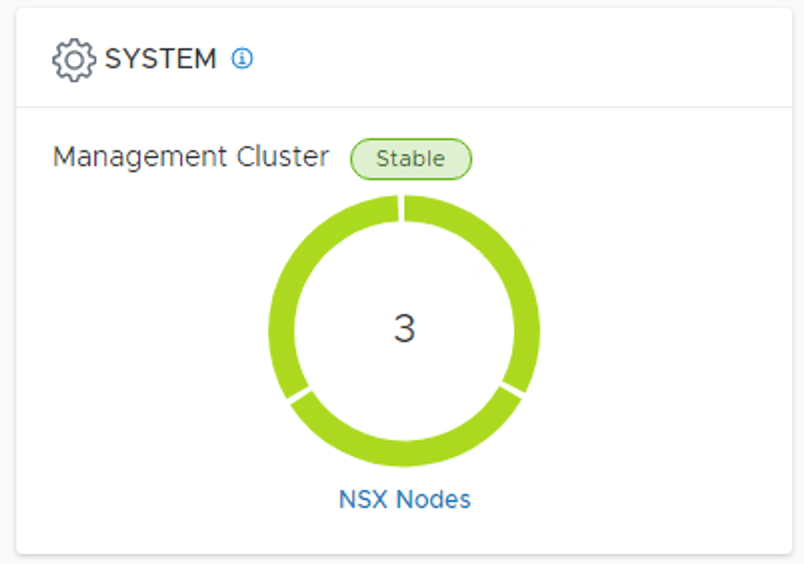
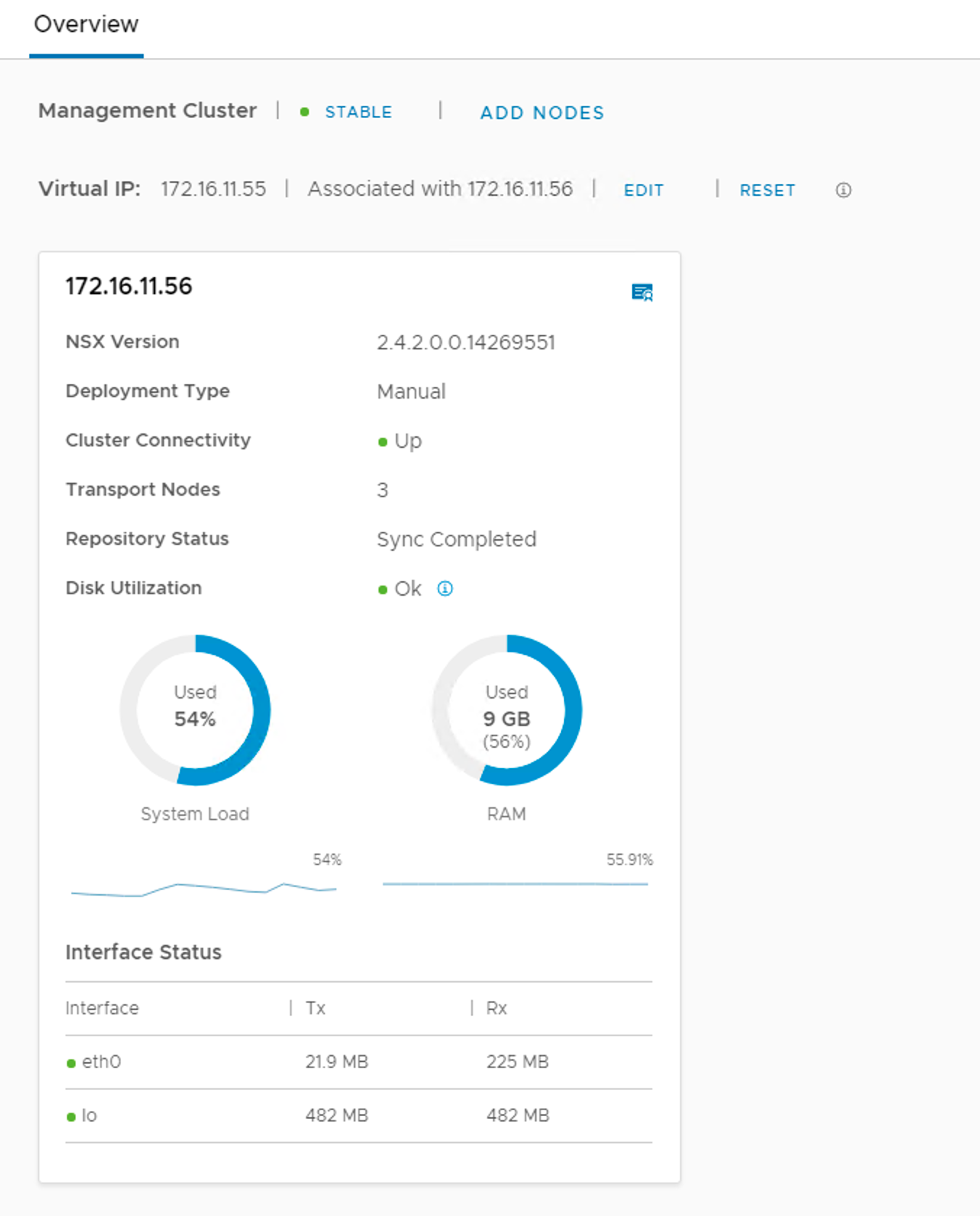
The NSX-T management cluster is currently in a healthy and stable state. We see three manager nodes connected and synced. Life is good.
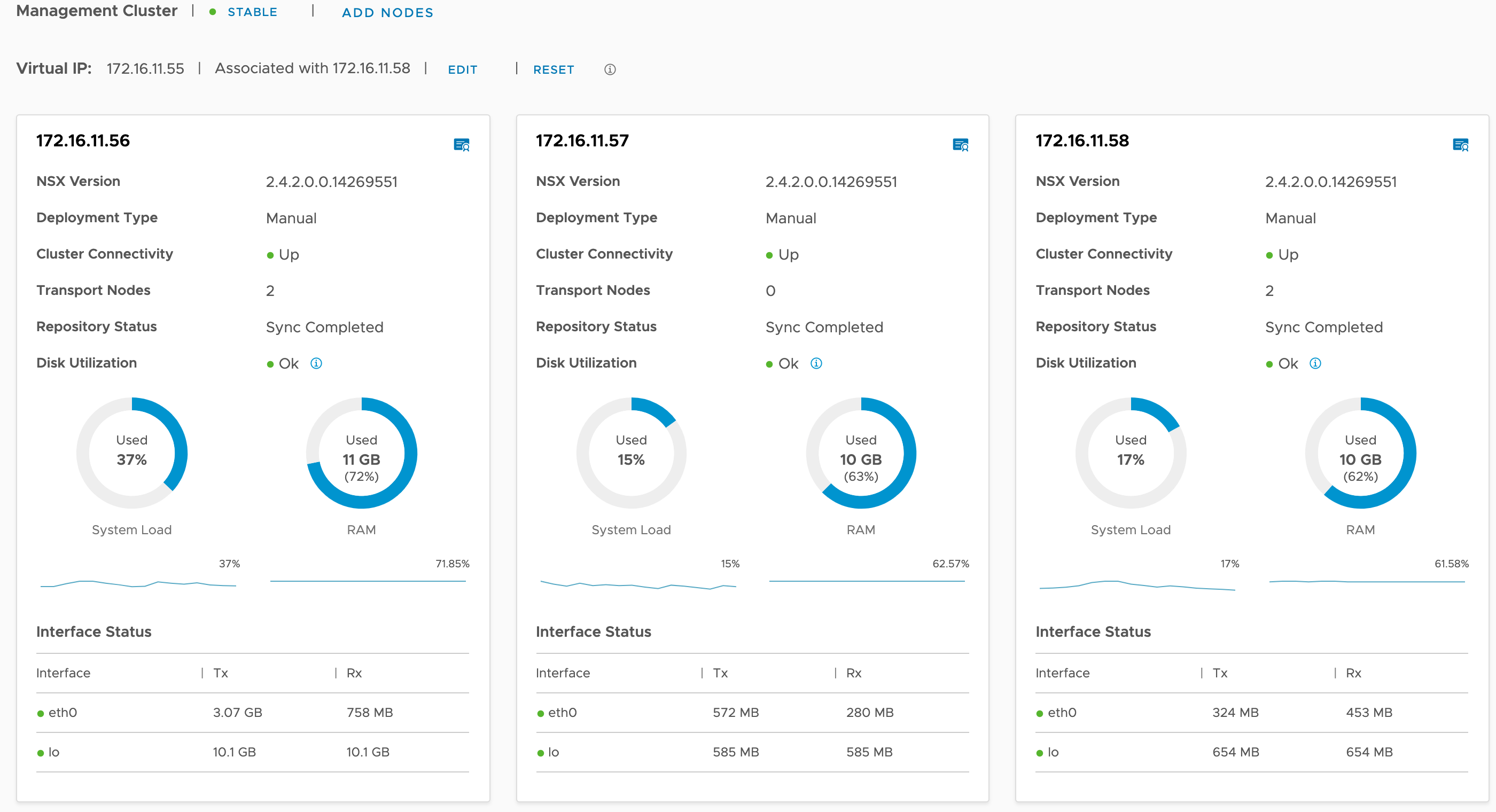
Backup is configured and seems to be working fine too:

In other words, we’re ready for some mayhem!
One manager/controller node down
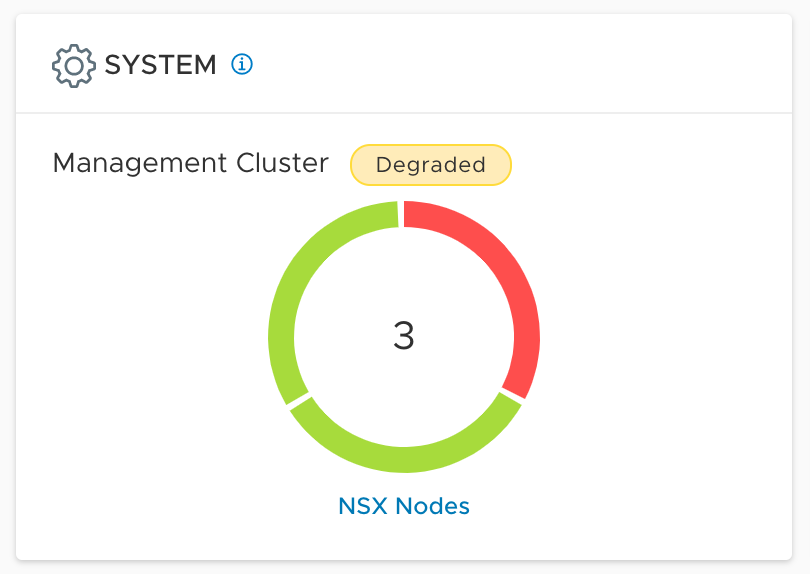
One of the management/controller nodes is gone. Somebody accidentally deleted the virtual appliance. It happens (in my lab).
The “get cluster status” NSX manager CLI command output clearly shows that the group status is degraded and that one of the nodes is down:

Even though the management cluster is now running in a degraded state, the majority of the cluster is still up and running (we have quorum) and NSX-T management operations aren’t affected at this point.
It’s not an optimal situation and we do want to return to a stable three node management cluster as soon as possible.
One manager/controller node down recovery
To recover from a one node failure we simply need to deploy a new manager/controller appliance that will replace the missing one.
We’ll first remove the orphaned node from the management cluster using the “detach node <node-id>” NSX manager CLI command:

The management cluster now returns to a stable state:

This is just a cosmetic improvement of course. We still need to deploy a new manager/controller appliance and join it to the cluster to get back to a production-grade management cluster.
Joining the new appliance to the cluster with the “join” command:

And after 10 minutes or so we once again have a stable three node management cluster. Easy!
Two manager/controller nodes down
Is a two nodes down scenario all that different from the previous one? The answer is yes.
With two nodes missing, the cluster loses quorum and can’t operate as a cluster anymore. The management plane goes into read-only mode. It’s not a disaster, but not a good situation either.
You’ll notice things like not being able to connect to the cluster’s VIP anymore and when logging in to the surviving node’s UI directly you are greeted with something like this:

We need to fix this, but how?
Two manager/controller nodes down recovery
We first need to deactivate the cluster. We do this by running the “deactivate cluster” manager CLI command on the surviving node:

This leaves us with a single, but operational manager/controller node. We should now be able to login to the manager UI on the VIP address again.
Checking under System > Overview we see a single operational node:
From here we can just deploy two new manager/controller nodes, join them with the surviving node to form a cluster, and get back to this:
Three manager/controller nodes down
Now we lost all three of the manager/controller nodes. We are running NSX-T without a management plane (and central control plane for that matter). Don’t panic! Packets are still flowing as the the data plane is not affected by the management plane outage remember?
But of course, it’s now just a matter of time before things will get really problematic. We need to do something.
Three manager/controller nodes down recovery
Without any surviving nodes the only option we have is to perform a restore from an NSX-T backup.
The first step here is to deploy a new manager/controller appliance. Once deployed we need to configure and perform a restore.
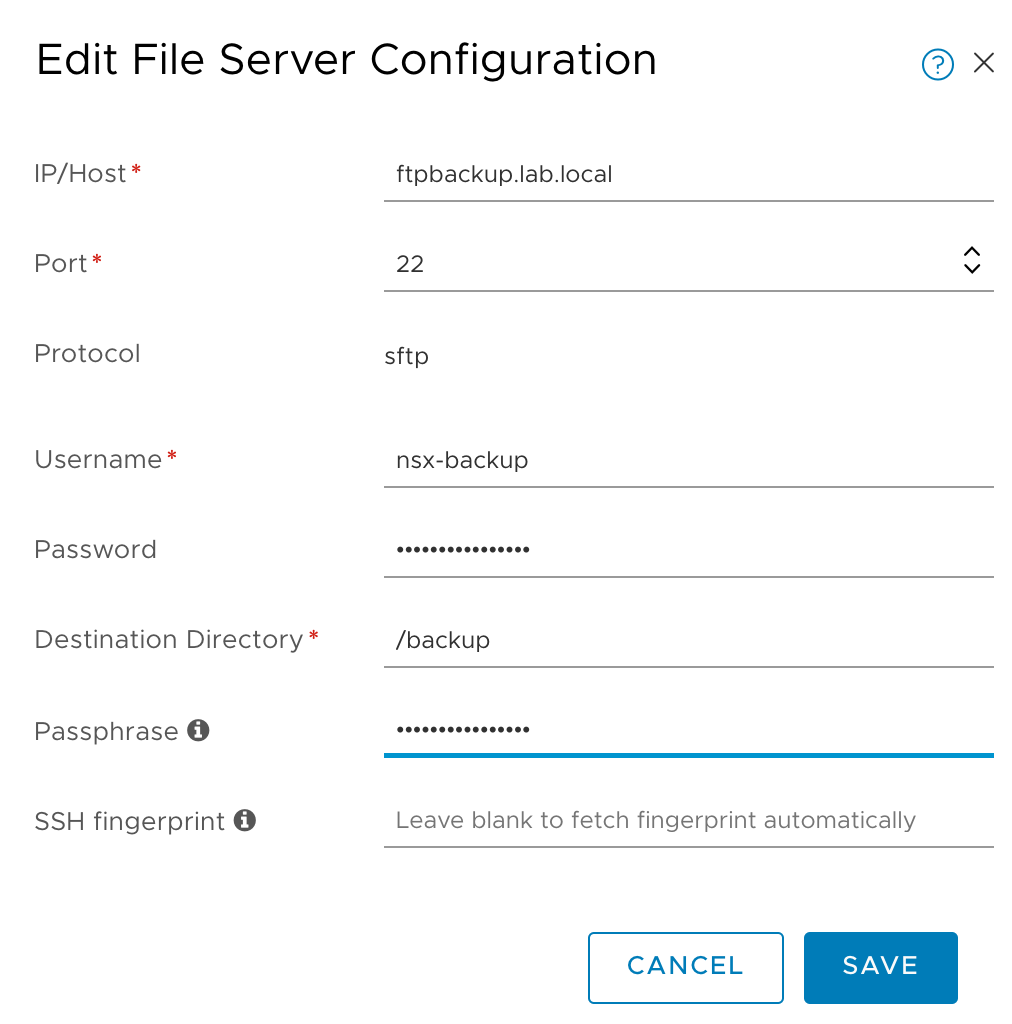
Navigate to System > Backup & Restore > Restore. Click on Edit to enter the details of your SFTP server containing the NSX-T backups:
After clicking on Save you should be presented with a list of the available backups:
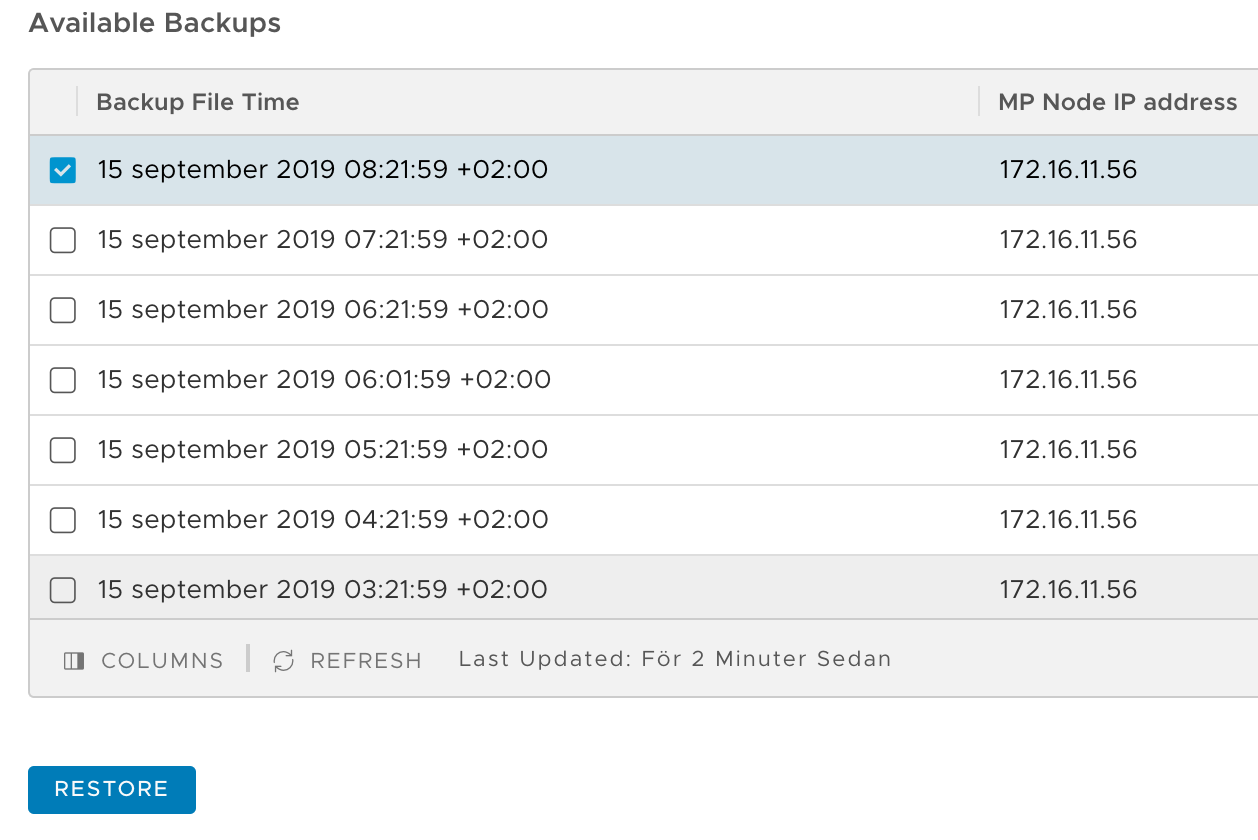
Pick the backup you want to restore from and click Restore. Read the warning message. It tells you what to expect during the restore process:
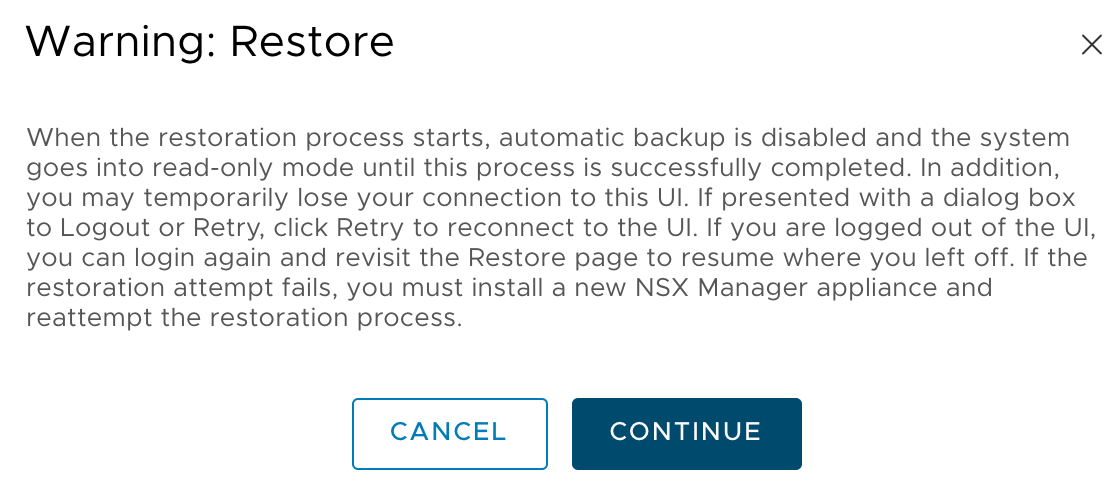
Pretty soon after starting the restore you are disconnected from the UI. After 10 minutes or so we should be able to log in again. When navigating to System > Backup & Restore > Restore, the following message is displayed:
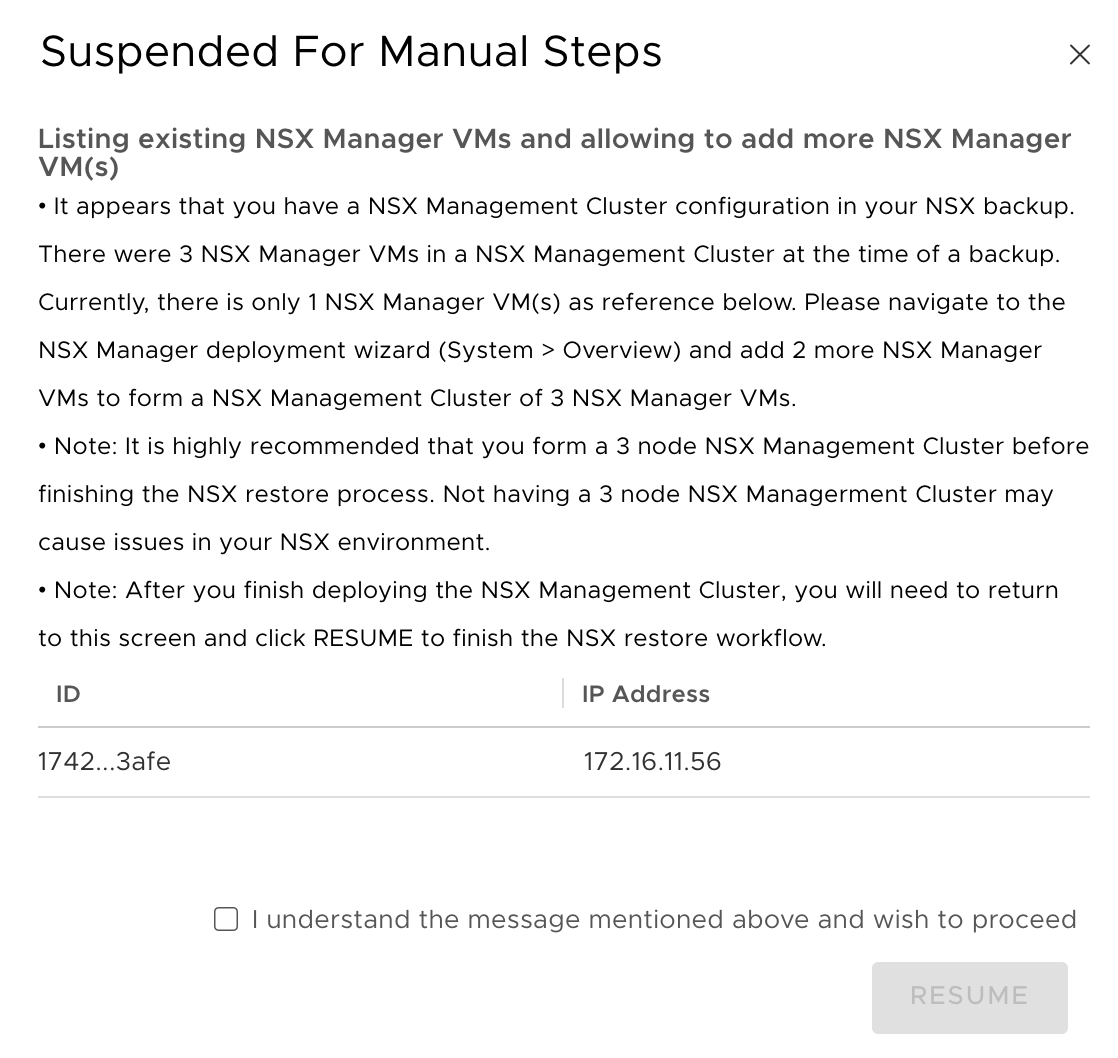
Okay, this makes sense. We’ll deploy two more appliances, form a cluster, and then resume the restore process. Once we’ve done that we should see the following confirmation under System > Backup & Restore > Restore:
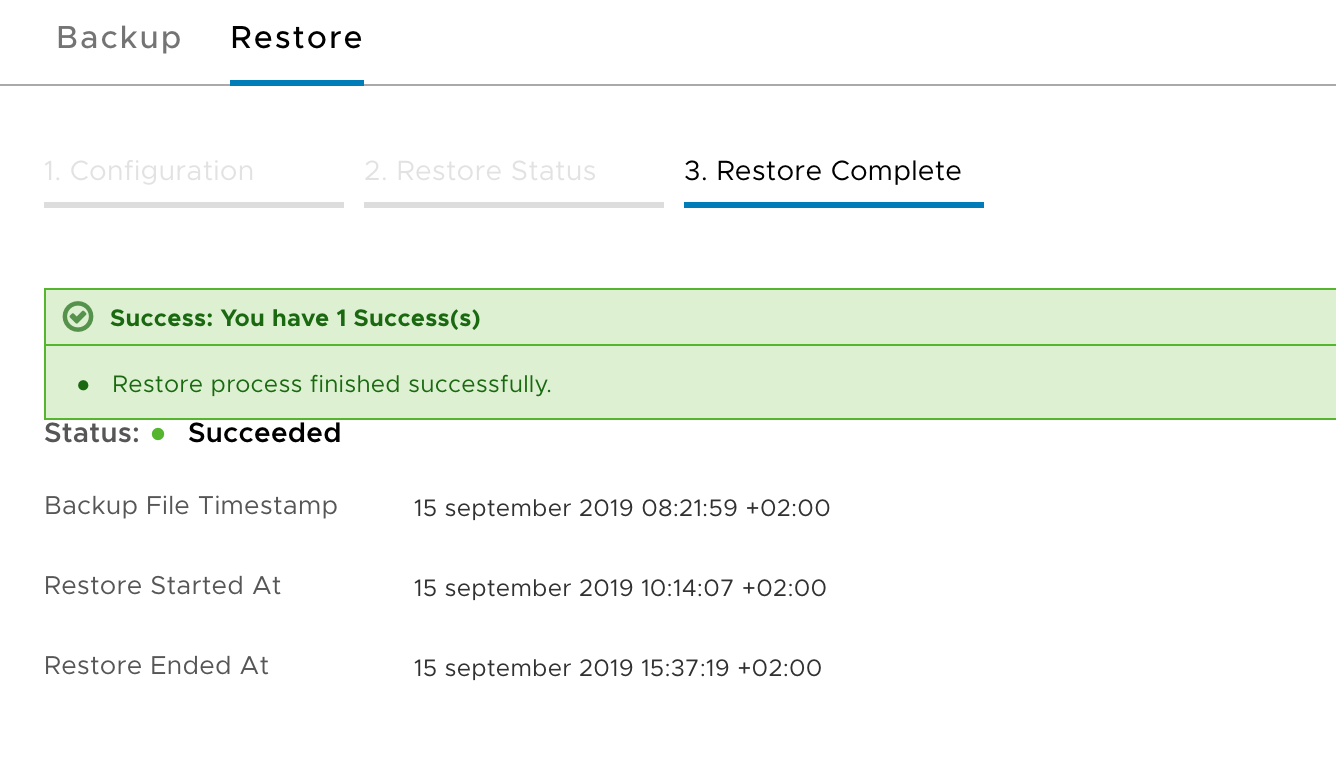
Don’t mind the timestamps in the screenshot above. That was just me taking a break 😉 The whole recovery process, deployment of manager nodes included, actually took less than an hour. Not too bad.
Summary
Recoverability of the NSX-T management plane is rather good I would say. We went through a couple of failure/recovery scenarios:
- Loss of one manager/controller node:
- clean up orphaned node
- deploy new node
- Loss of two manager/controller nodes:
- deactivate cluster
- deploy two new nodes
- Loss of three manager/controller nodes:
- deploy new node
- restore from NSX-T backup
- deploy two more nodes
- finish restore operation
In my very simple lab environment it was never any problem to get the management plane back up and running again. Thanks to NSX’s architecture the actual networking (data plane functions) was not affected at any point during the management plane outages.
In theory size and complexity of an NSX-T environment shouldn’t matter much for management plane recovery procedures. As I said before, open a VMware support case if anything ever breaks in your NSX-T environment. It’s the smartest thing to do.

Leave a comment