
Welcome back! In part 1 we had a look at some NSX-T management plane failure scenarios and how to recover from them. In this part we continue to investigate NSX-T recoverability at the data plane and more specifically the NSX Edge.
Quick note
If you ever experience an issue in your NSX-T production environment, the first and only thing you should do is open a VMware support request. Highly skilled experts who are dealing with all kind of NSX-T issues on a daily basis will help you in the best possible way with your specific issue.
NSX data plane failure & recovery
Most will agree that failures at the data plane are more critical than for instance failures at the management plane. After all, the data plane is where the network packets that really matter are flowing around. Failures at the data plane can potentially impact service availability.
Luckily, the NSX data plane is robust by design. Largely distributed and where it’s centralized it’s also clustered. Combine this with a proper design for the physical and logical components and you’re looking at a pretty solid solution.
But sure, things can break down and when they do it’s important to understand how to get back on track again.
The lab environment
We’re still using the same small lab environment as in part 1. I just added a VM in the compute cluster for today’s article. Below is a diagram showing the main components from a high level perspective.

The NSX Edge
The NSX Edge is a centralized, often clustered, component. It provides a range of gateway services, but one of its main responsibilities is routing traffic between NSX logical networks and the physical network.
The worker bees of the NSX Edge are the edge nodes. They are available in two form factors (virtual machine and bare metal) and are organized in one or more edge clusters.
In my lab environment the NSX Edge consists of of two edge node VMs and one edge node cluster.
Let’s have a quick look at the deployment details of one these edge node VMs.
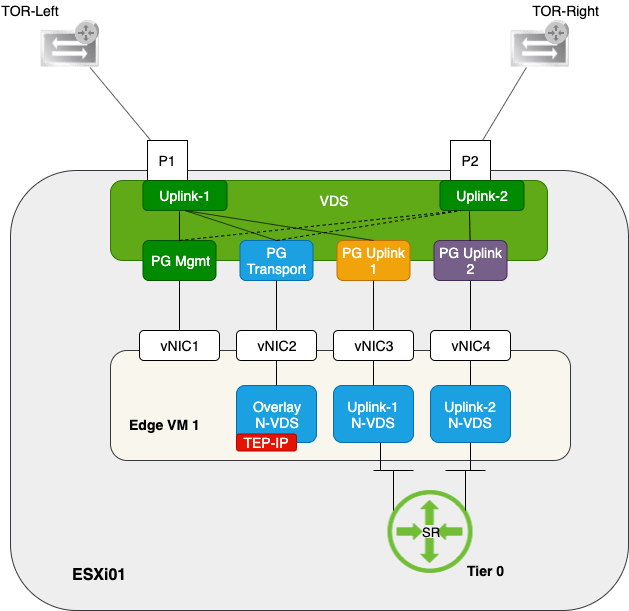
A pretty common NSX-T 2.4 edge node deployment configuration for the VM form factor.
Below the layer 3 topology running on top of the NSX Edge.
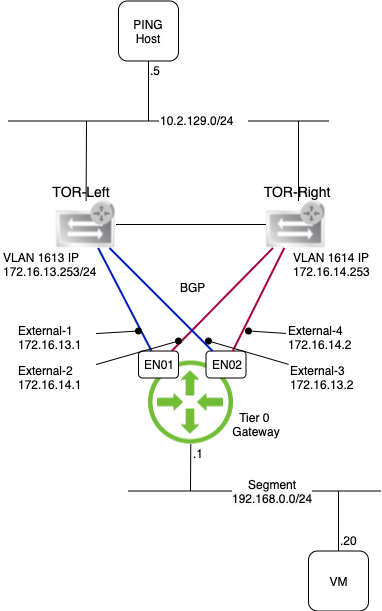
As you can see the layer 3 network is making good use of the lower layer’s redundant paths.
Lastly, the Tier 0 gateway in this lab has been set up with an Active-Standby HA mode.

Current state of the NSX Edge
Life is good at the edge. The edge node VMs are up and running.

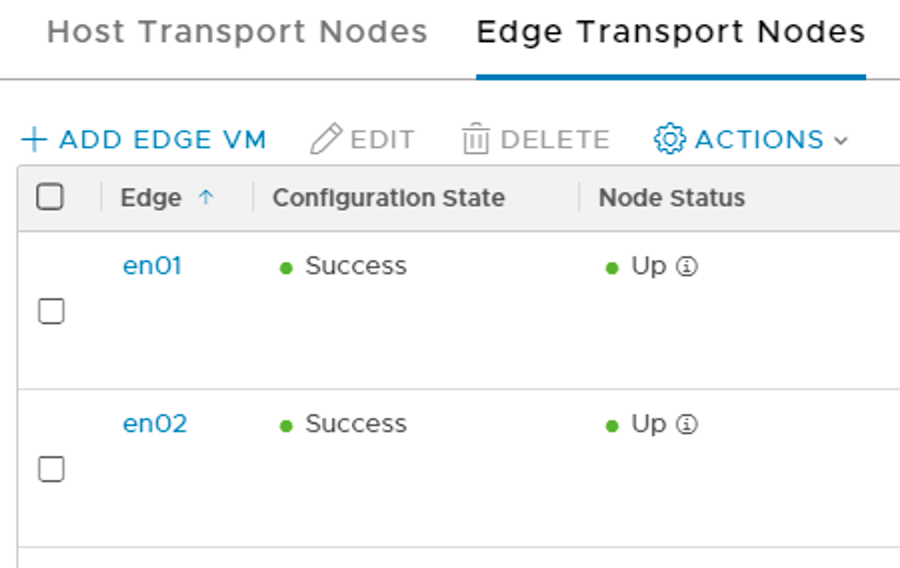
The edge transport nodes configuration state and node status are looking good.
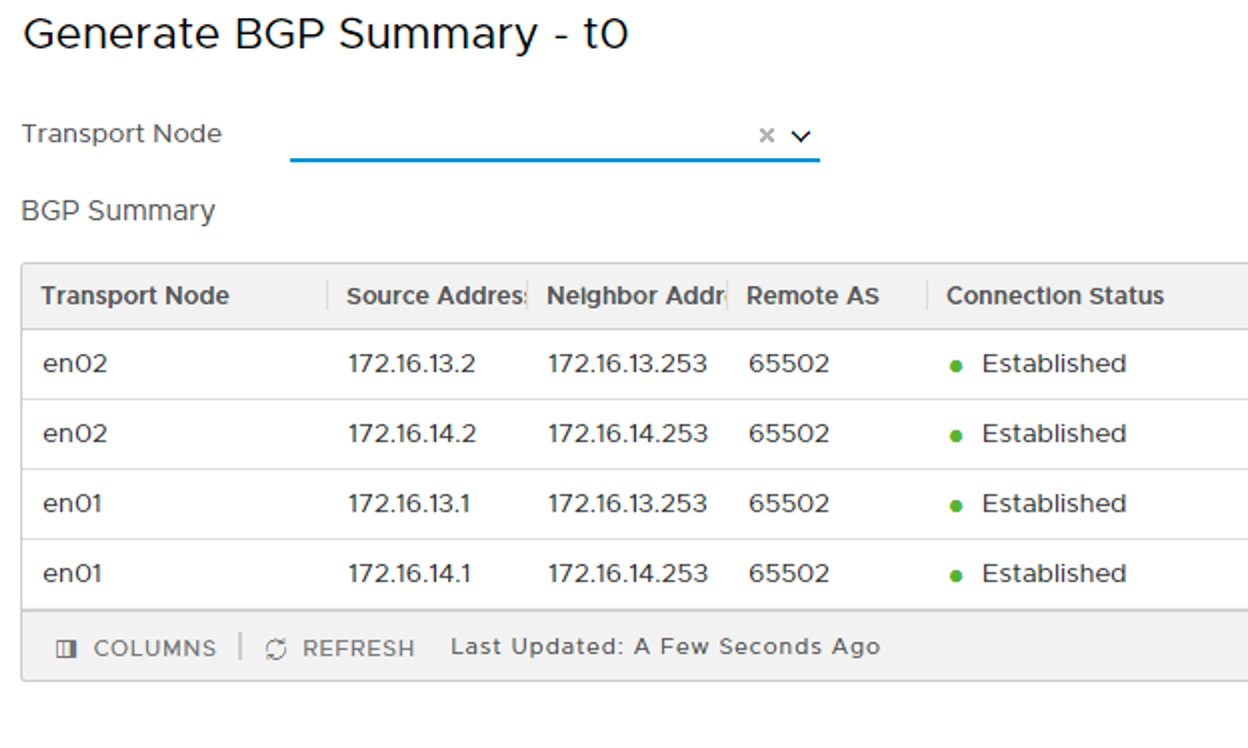
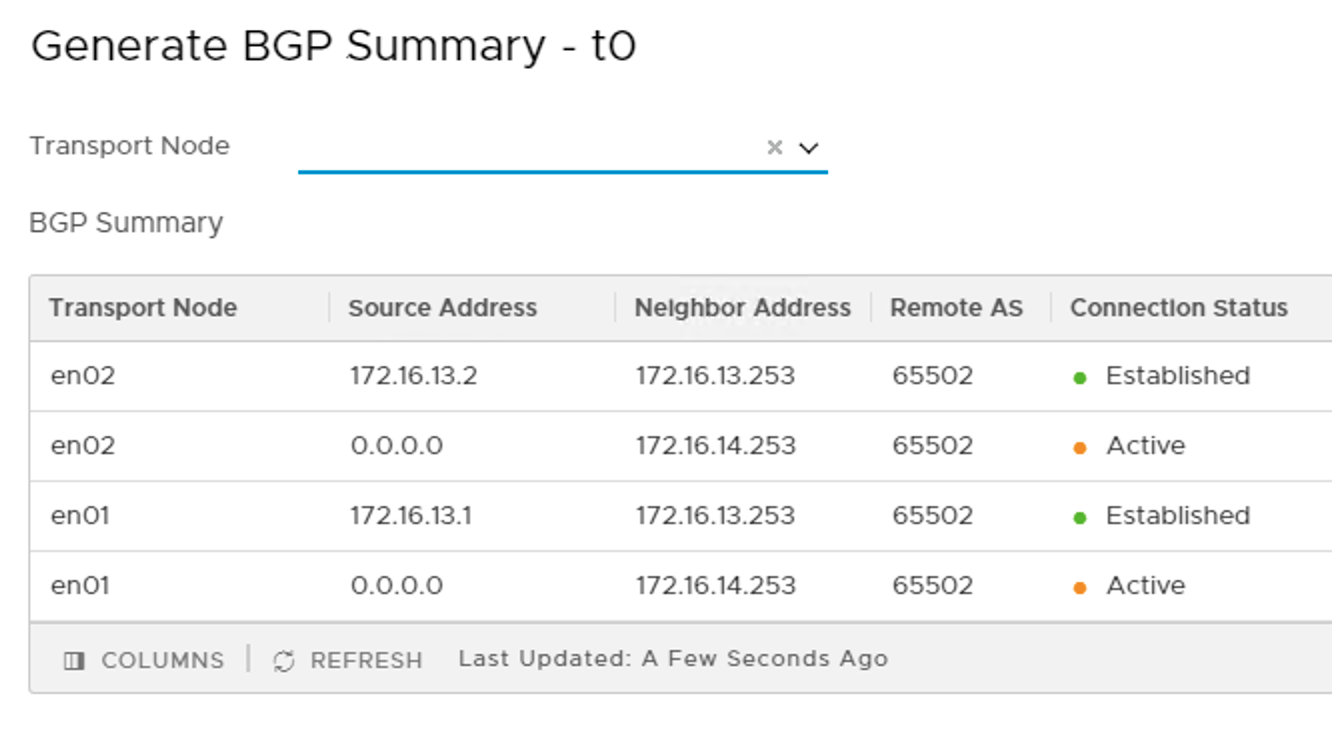
The Tier 0 gateway’s BGP summary shows that BGP connections are established with both of the TORs.
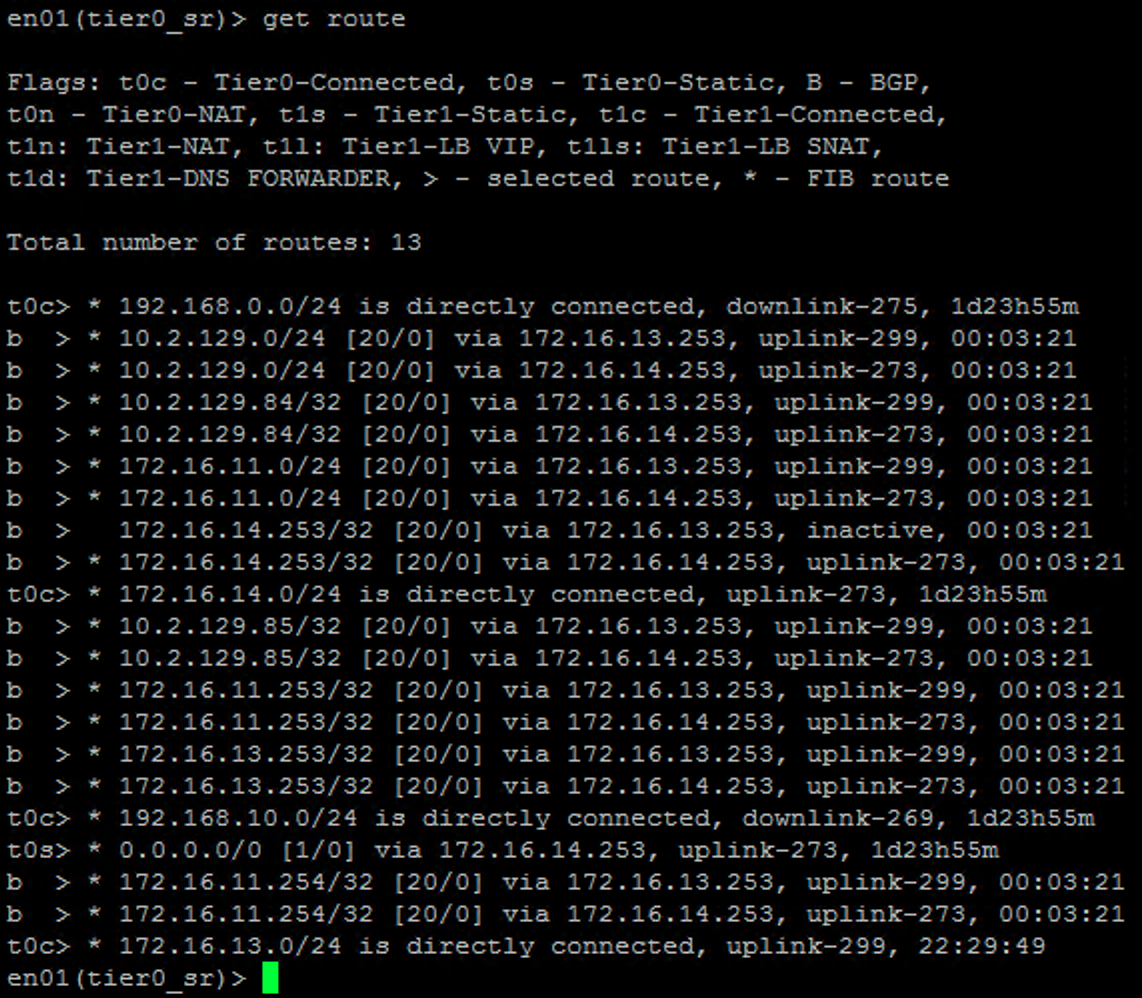
The Tier 0 gateway’s routing table contains IP routes advertised by the TORs through BGP.
And last but not least the VM in the compute cluster can access the physical network. A “traceroute” to the PING host on the physical network shows that traffic is routed to TOR-Right (172.16.14.253) at the moment:

North-south networking is running beautifully! What can possibly go wrong on a day like this?
TOR down
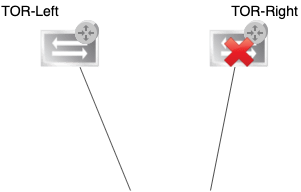
Not exactly an NSX Edge failure, but definitely a failure scenario that concerns the NSX Edge.
TOR-Right broke down. What’s the impact? Let’s have a look.
The BGP summary indeed shows us that we’ve lost connection with TOR-Right. BGP connections with TOR-Left are still intact though.
The Tier 0’s routing table now only contains BGP routes advertised by TOR-Left.

All of this is expected, but how is the data plane affected by this TOR failure?

It seems to be working fine. Sure, the “traceroute” reveals that traffic is now passing through TOR-Left (172.16.13.254), but that’s about it.
The redundant infrastructure and BGP making use of that ensured that this TOR failure had minimal impact on the NSX data plane.
TOR down recovery
Basically we would just rack and stack a new TOR, configure it, and restore redundancy. The only thing we need to do within NSX is verify that the BGP connections are restored.
Edge node down
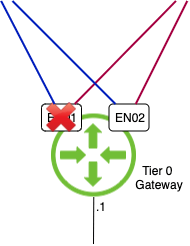
Last time I checked there were two edge node VMs in that Edge cluster. en01 is gone!

What’s the impact? How do we recover?
Let’s first investigate the impact this failure has on the north-south traffic.
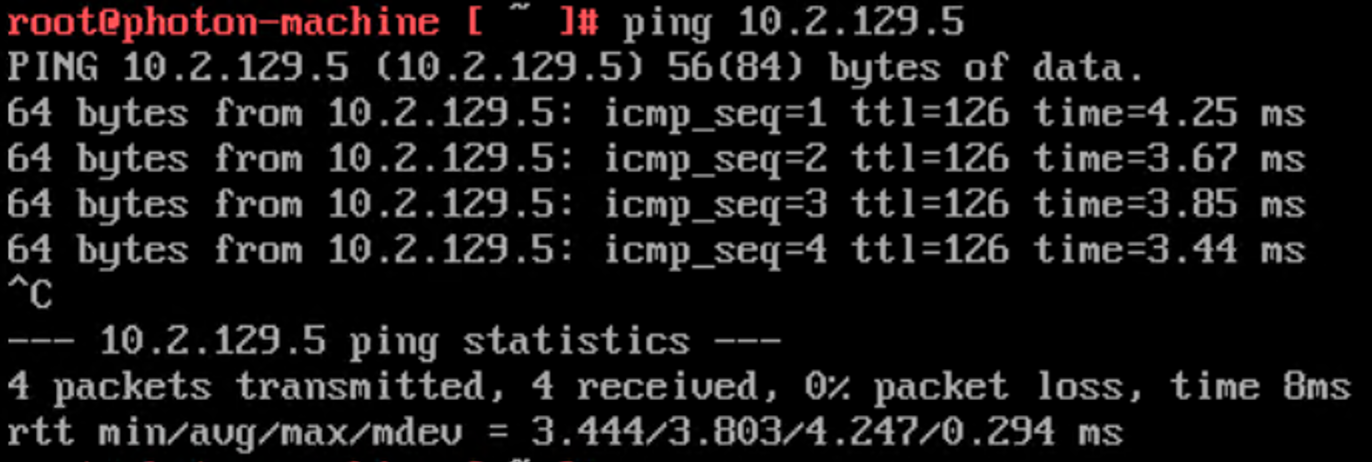
Alright, none whatsoever.
The VM can still reach the physical network. The surviving edge transport node must have taken over the duties of the failed node.
But of course, the NSX Edge is now running on a single edge transport node and NSX Manager clearly shows us that we are dealing with a degraded state.
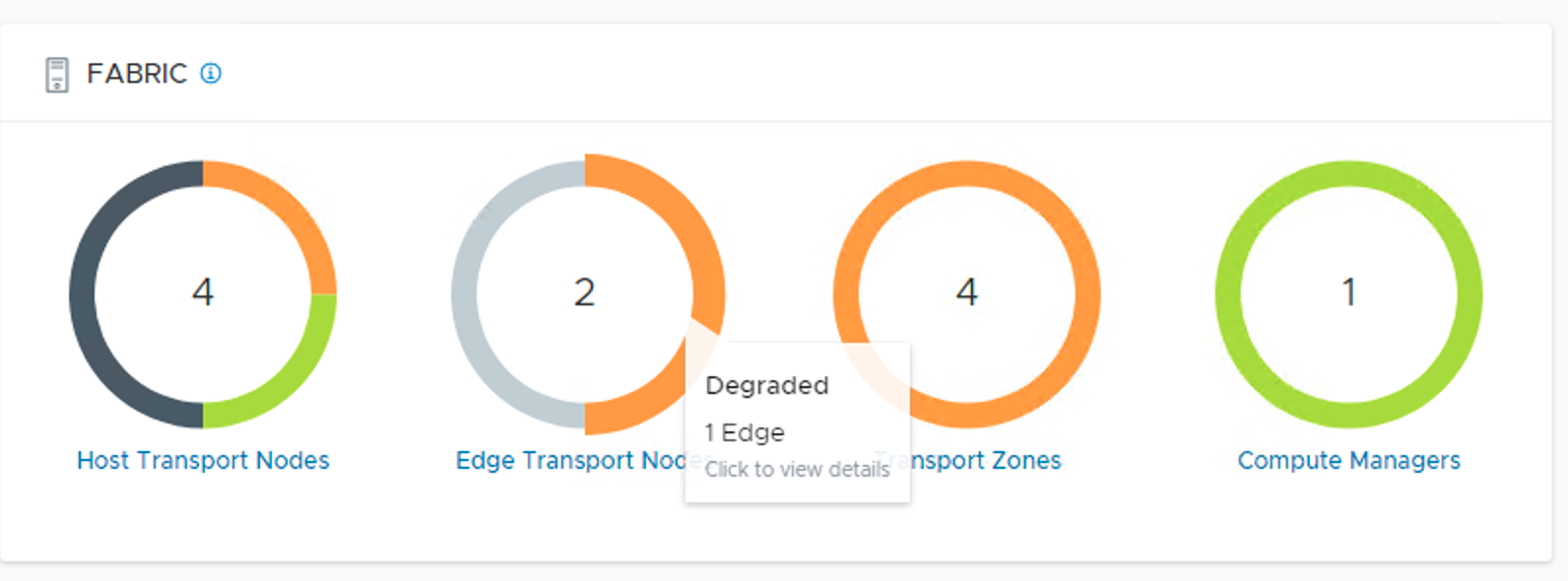
Without a standby node we’re living on the edge (pun intended). We need that second transport node up and running again.
Edge node down recovery
In a situation like this it’s good to remember that there’s nothing unique about an edge node. During its lifetime it is much like a container receiving and executing configuration from the management plane. In other words, losing the edge node is in itself nothing traumatic. We just need to get a new one.
The first step when recovering from a permanent edge node failure is to deploy a new edge node. Once it’s deployed three edge transport nodes are listed in the NSX Manager UI.
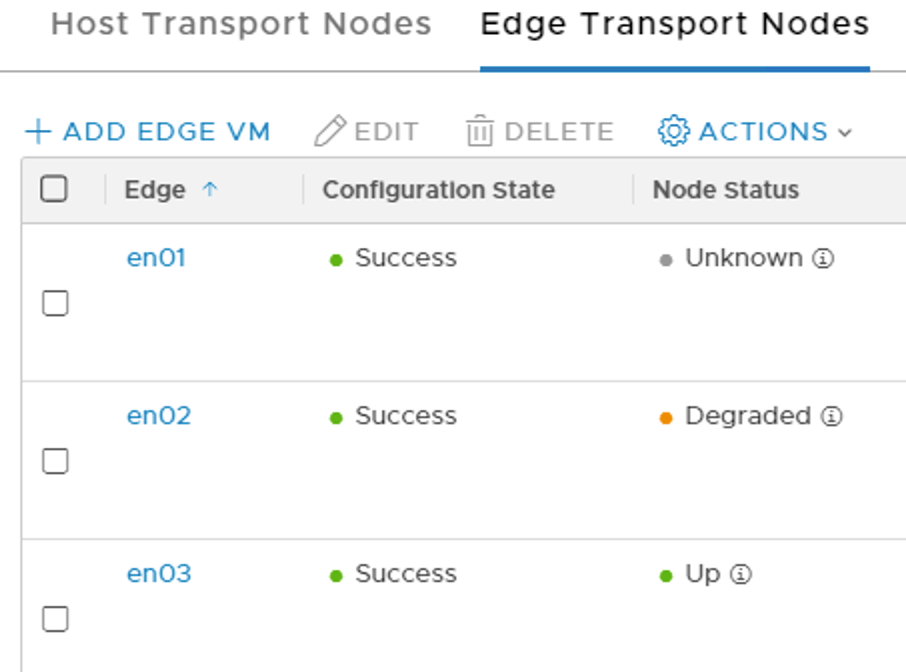
- en01 with status “Unknown” is the node that is missing.
- en02 with status “Degraded” because it can’t find its HA buddy.
- en03 with status “Up” is alive and happy but not doing much.
The second step is to tell the management plane that we want to replace the missing edge transport node with the one we just deployed.
This is done under Edge Clusters in the NSX Manager UI (or via the API).
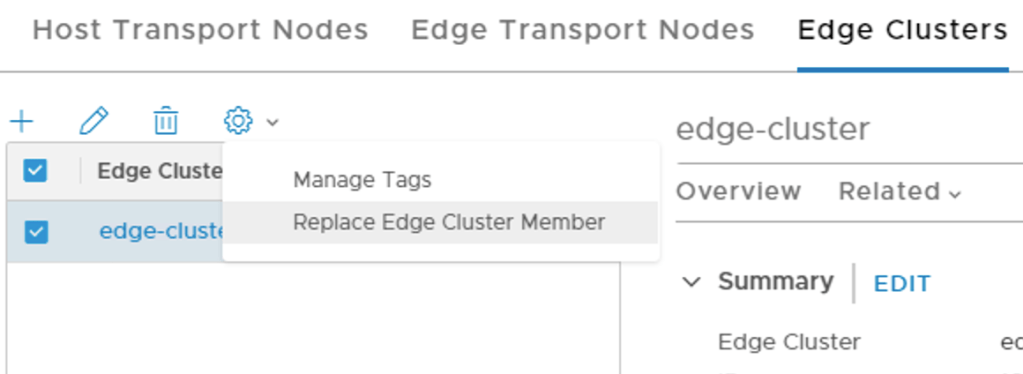
After clicking the small gear icon we select Replace Edge Cluster Member. This starts the process of re-mapping logical network configuration from one edge transport node to another.
In our scenario we want to re-map from en01 to en03.

If the edge transport node would still be operational, we would put it in maintenance mode here to minimize data plane disruptions. In our failure scenario the node is already gone so maintenance mode is not relevant.
After clicking Save the management plane comes into action and links configurations and other related logical network constructs to the new edge transport node.
Once the process is done we can delete the orphaned edge transport node and after a minute or so we’re seeing two healthy edge transport nodes again.
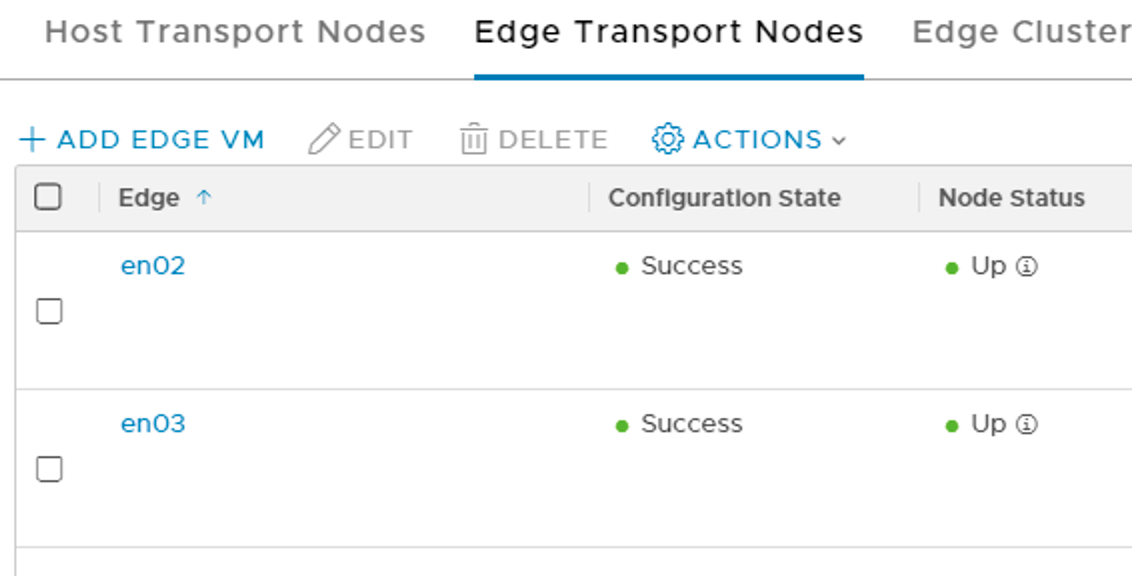
A look at the Tier 0’s logical router ports shows us what happened.
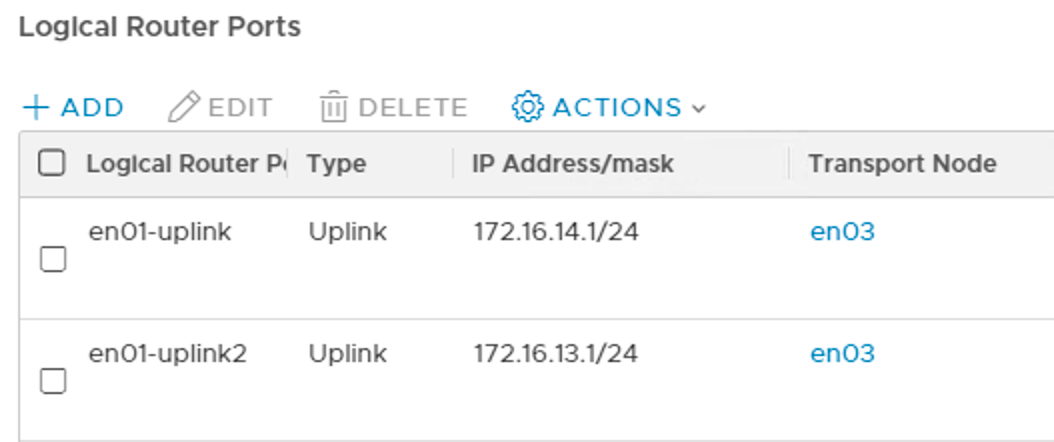
Two of the logical router ports previously mapped to en01 have been relocated to en03.
BGP connections are established again.
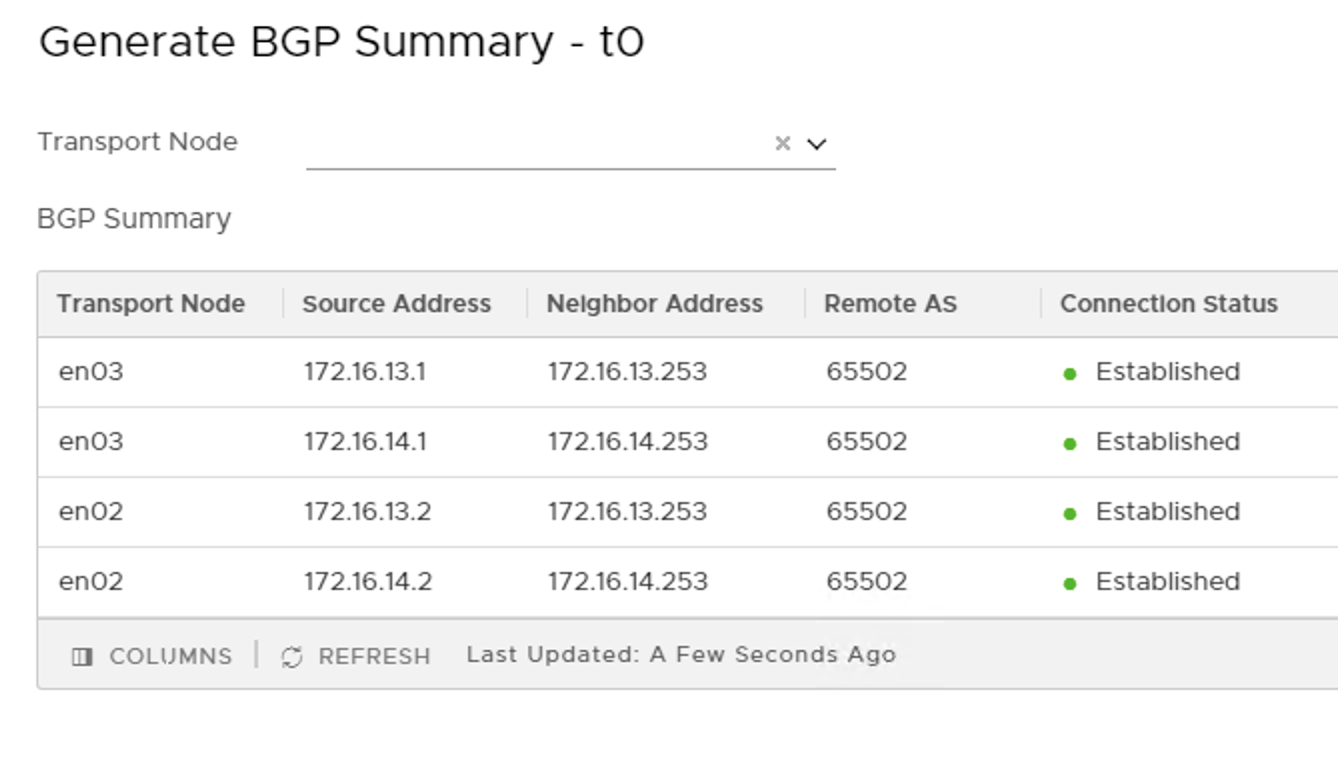
Replacement successful! The fabric’s state is restored to normal operations.
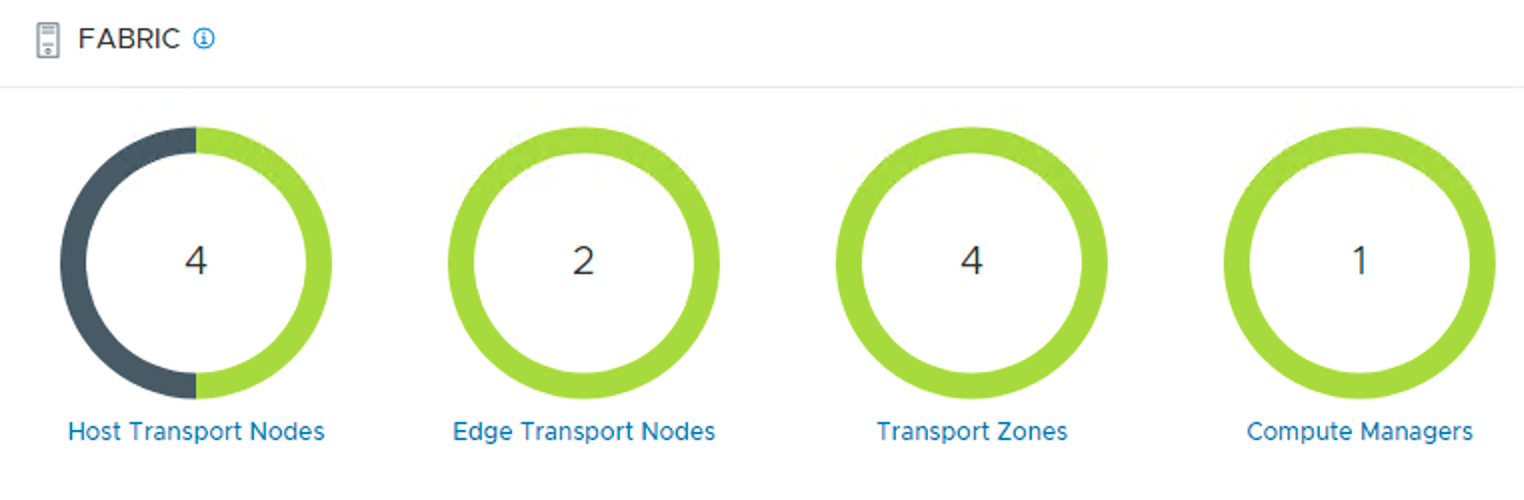
Summary
Today we looked at two failure scenarios concerning the NSX Edge:
- Failure of a top-of-rack switch
- limited impact on the data plane
- Failure of an NSX edge node
- deploy new edge node
- run edge transport node replace process
- remove orphaned edge transport node from fabric
Not too bad. This is a small environment, but the recovery procedures will be largely the same regardless of environment size.
Sure, more things can break. An ESXi host hosting an edge node, a physical NIC, cables, and so on. The bottom line is that unless we’re dealing with a complete meltdown, a properly designed NSX Edge will minimize the impact of component failure and make recovery a piece of cake.

Leave a comment