When we talk about private cloud, we often end up talking about automation.
That makes sense. Nobody wants to build a cloud platform where every request still ends up as a ticket, a manual change, and a meeting. Self-service is part of the point.
But self-service without guardrails is not really cloud. It is delegated infrastructure access with a nicer user interface.
That is why I think this is one of the more interesting parts of VMware Cloud Foundation 9.1 and VCF Automation. Users can request virtual machines, namespaces, VKS clusters, networks, and other services, but the platform team can also define the boundaries around that consumption up front.
- Who can consume what?
- Where can workloads land?
- How much can a tenant consume?
- Which networks can they attach to?
- When should temporary workloads disappear again?
Those boundaries are what I mean by guardrails in this context.
In this article I am focusing on the All Apps organization model in VCF Automation. That is the model built around vSphere Supervisor, regions, region quotas, projects, namespaces, namespace classes, VPCs, and the IaaS services used to consume VMs and Kubernetes-based services. I am not trying to cover the VM Apps organization model or the older Aria Automation-style consumption model here.
Guardrails are not a single feature
It is tempting to look for a specific feature in VCF Automation called “guardrails”. I do not think that is the right way to look at it.
The guardrails are really the result of how the platform model is put together. Organizations, regions, quotas, projects, namespaces, namespace classes, VPCs, catalog items, policies, identity, and extensibility all contribute in different ways.
Some of this becomes hard limits. Some of it becomes access control. Some of it becomes lifecycle management or placement control. And some of it is simply about giving users sensible defaults instead of making every request a small design exercise.
That last part is easy to underestimate. A shared platform should not rely on every consumer understanding the full architecture. It should encode enough of the architecture so that normal users can consume services without constantly stepping outside the intended design.
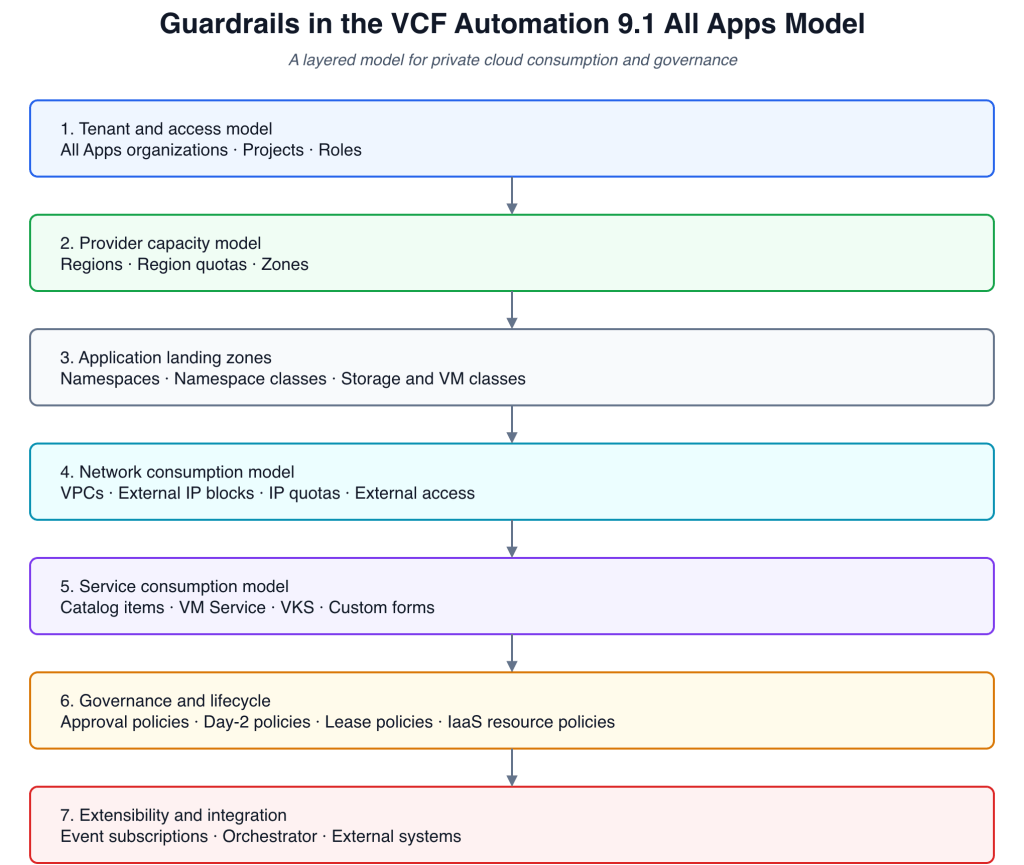
Guardrails in the VCF Automation 9.1 All Apps model, shown as layered platform controls.
The organization is the tenant boundary
At the top of the All Apps consumption model we have the organization.
An organization can represent a tenant, a customer, a department, a line of business, or some other administrative boundary. Exactly what it represents depends on the environment.
In an enterprise, I would not automatically create an organization per application team. That would probably create too much overhead. I would rather use organizations for larger boundaries where identity, quota, catalog, networking, and governance need to be separated.
In a service provider or internal platform provider model, the mapping is more obvious. One organization can represent one customer, agency, department, or tenant.
The key point is that the organization becomes the first real consumption boundary. It groups users, policies, resources, services, catalog entities, and access control.
This is also where VCF 9 starts to feel less like infrastructure with automation added on the side, and more like an actual platform model. The provider is not just handing consumers access to vCenter and NSX objects, but exposing more controlled abstractions through VCF Automation.
Regions and quotas define what can be consumed
A region in VCF Automation represents a collection of infrastructure resources. In practice, it maps to one or more Supervisor-enabled clusters and provides compute, memory, storage, and networking capacity.
The region by itself does not give an organization access to anything. That access is controlled through a region quota. The quota defines how much of the region an organization can consume, but also which capabilities are available. CPU and memory limits, reservations, VM classes, storage classes, storage limits, and zones are all part of the model.
This is also why I see region quota as one of the defining constructs of the All Apps model. It is the mechanism that connects provider-managed infrastructure to organization-level consumption.
I think this is one of the more important guardrails in the design because it changes the nature of self-service. Without quota, self-service depends too much on trust and informal agreements. With quota, it becomes an allocation model. The provider can give an organization access to capacity without giving it unlimited access to the platform.
It also makes the conversation with the business or application teams more concrete. Instead of saying “please don’t use too much”, the platform team can say “this is the capacity envelope assigned to you”. For a shared private cloud platform, that is a much healthier starting point.
Projects are where teams start to consume
Inside an organization, projects are closer to the application team or workload team boundary. Users and groups are added to projects, catalog items can be shared with projects, and resources are provisioned into namespaces that belong to those projects.
I like this model because it avoids making organizations too granular. The organization can remain the tenant or major administrative boundary, while projects can represent application teams, environments, or delivery groups.
For example, one organization might represent a department, with multiple projects for application teams, separate namespaces for application environments, and different policies depending on whether the project is used for production, test, or development.
That gives the platform team a useful hierarchy without exposing every underlying infrastructure detail.
Namespaces are the application landing zone
Namespaces are where the consumption model starts to become practical for application teams.
A namespace gives a team a defined place to deploy into. Compute, memory, storage, and networking are assigned to that namespace, and VMs, VKS clusters, volumes, and other services can then be provisioned inside that boundary.
That is a cleaner model than giving every team direct access to the underlying infrastructure and expecting them to interpret the platform design correctly. The application team gets a place to land, while the platform team still controls the size of that place, which storage classes can be used, which VM classes are available, and which networks are attached.
In this context, a namespace is not just a Kubernetes construct. It becomes a cloud consumption boundary for an application or environment.
Namespace classes make the model repeatable
If every namespace is created manually with custom settings, the model will eventually drift. Namespace classes help avoid that by turning common namespace patterns into reusable templates.
A namespace class can define CPU limits, memory limits, reservations, storage limits, VM classes, storage classes, content libraries, and zone placement. This is the kind of construct I like in a platform design because it makes the intended consumption model repeatable without forcing every application team to understand all the underlying design choices.
Instead of asking each team how much CPU, memory, storage, and which capabilities they need from scratch, the platform team can define a small number of sensible options.
For example, the platform team might define classes such as dev-small, test-medium, prod-medium, prod-large, gpu-enabled, or restricted.
The exact names are not important. What matters is giving users enough choice to be useful, without turning every namespace request into a small design exercise.
Networking guardrails are critical
Networking is one of the areas where self-service can quickly become problematic. It is useful to let application teams consume network services, but it is usually not a good idea to expose the full networking design to every consumer.
In VCF Automation, the networking model uses constructs such as VPCs, connectivity profiles, transit gateways, IP blocks, external connections, NAT, VPN, and load balancing. The provider defines the available building blocks, while organization and project users consume them through controlled abstractions.
IP consumption is part of that model as well. External IP blocks are not just pools of addresses that organizations can freely consume. The provider can apply IP quotas to control how many individual IP addresses or CIDRs an organization can allocate, and can also restrict the largest subnet size that can be requested. That matters because IP address space is often one of the easiest shared resources to waste if it is not governed.
This fits well with how I think NSX should be used in a modern VCF platform. NSX should provide the network and security foundation, but most consumers should not need to work directly with every NSX object underneath. They need a network model they can consume safely, not unrestricted access to the implementation details.
The platform team still owns the routing model, external connectivity, IP allocation boundaries, edge capacity, and security architecture. VCF Automation helps expose those capabilities at the right level.
Catalog items reduce unnecessary freedom
There is a difference between self-service and free-for-all. A catalog item gives users a controlled way to request something useful, whether that is a VM, a namespace, a VKS cluster, an application blueprint, or a workflow.
The value is not only in the request itself, but in the design work that happens before the item is published. The platform team or organization administrator can decide what a good request should look like, which inputs should be exposed, which defaults should be used, and which options should be hidden.
This is also why I think custom forms are more important than they might look at first. They are not just there to make the request page nicer. They can hide complexity, validate input, simplify choices, and reduce the number of ways users can get something wrong.
A good catalog item should be easy, almost boring, to consume. The design work should happen before the item is published, not every time someone requests it.
Policies are the visible guardrails
When people think about governance in automation platforms, they often think about policies first. That makes sense, because approval policies, lease policies, day-2 action policies, and IaaS resource policies are the most explicit governance constructs in VCF Automation.
Each of them solves a different problem. Approval policies can require human approval before a deployment or day-2 action continues. Lease policies help prevent temporary workloads from living forever. Day-2 action policies control what users are allowed to do after something has been deployed. IaaS resource policies can enforce more technical constraints around what resources are allowed inside namespaces.
They are all useful, but I would not start with approval policies. If everything requires approval, the platform probably has not encoded enough of the design into hard guardrails. At that point, the approval process becomes a substitute for platform design, and that is not where I would want to end up.
I would rather use quotas, namespace classes, project scoping, RBAC, catalog design, and IaaS resource policies to prevent bad outcomes automatically. Then use approvals for exceptions, high-cost requests, risky actions, or production-impacting changes.
Day-2 matters just as much as day-1
Provisioning usually gets most of the attention. That is understandable. The first thing people want to see from an automation platform is often whether it can deploy something at all.
But the operating model does not stop when the deployment is created. The next set of questions is just as important: can the user resize the VM, delete the deployment, extend the lease, add a disk, change network settings, or run a custom action?
Those actions can have just as much impact as the original request. In some cases they are more sensitive. Creating something in a controlled way is one thing. Changing or deleting something that already exists can be a bigger operational risk.
This is where day-2 action policies become useful. They allow the platform team to define which actions are available after deployment, and to whom. If the deployment process is governed but the operational lifecycle is wide open, the platform still has a gap.
Lease policies are simple, but powerful
Lease policies are not a new idea, but they are still one of the most useful guardrails. A lot of waste in infrastructure platforms does not come from bad intent. It comes from resources that were created for a valid reason and then forgotten.
That is especially common with test environments, proof-of-concepts, sandboxes, and other temporary deployments. The work gets delayed, the person who created the environment moves on, and eventually nobody knows whether it is still needed.
For those types of workloads, I would almost always use leases. They do not have to be aggressive, but there should be some kind of lifecycle expectation. Temporary resources should either be renewed because they are still needed, or reclaimed because they are not.
Production is different, of course. I would not want production workloads to disappear because someone forgot to click renew. But for non-production and temporary environments, lease policies are one of the easiest ways to keep the platform clean.
IaaS resource policies are where hard constraints belong
IaaS resource policies are interesting because they move beyond human approval and into admission control. Instead of asking someone to approve every exception, the platform can enforce certain rules before resources are created.
This is where you can control what types of namespace resources are allowed. For example, you might restrict which services can be used, which VM classes are available, which Kubernetes versions are acceptable, or how VKS clusters can be shaped.
That is closer to how I think platform engineering should work. The desired behavior should not only live in design documents, naming standards, or operational guidelines. Where it makes sense, it should be encoded into the platform itself.
At the same time, this is also where policy design needs some care. If policies overlap badly or contradict each other, users will not experience the platform as governed. They will experience it as broken.
For that reason, I would keep the first version simple. Start with a small number of clear policies that express real constraints, and expand when the operational consequences are better understood.
Identity and roles still matter
Guardrails are not only about resources. They are also about who can do what, and that is where the role model becomes important.
VCF Automation has provider-level roles, organization roles, and project roles. That makes it possible to separate platform administration, tenant administration, project administration, consumption, and auditing without giving everyone the same level of access.
This is another area where I would avoid over-engineering too early. I would rather start with a small number of clear personas:
- Platform provider administrator
- Organization administrator
- Project administrator
- Project user
- Auditor
Once those personas are clear, it becomes easier to decide what each of them should actually be allowed to do.
The worst outcome is usually not that you have too few roles in the beginning. The worse outcome is a role model nobody understands. If people cannot explain who is allowed to do what, the access model is already too complicated.
Extensibility fills the gaps
No platform product will know every rule an organization wants to enforce. There will always be things that depend on local processes, existing systems, naming standards, ownership models, or security requirements.
That is where event subscriptions, VCF Operations Orchestrator, APIs, and external systems become useful. They allow the platform to connect with the parts of the organization that sit outside VCF Automation itself.
In practice, that might mean validating names against a standard, creating tickets, updating a CMDB, applying metadata or tags, or enriching an approval based on cost center, data classification, or environment type. These are not always native product features, but they are still real platform requirements.
I would not use extensibility to compensate for a weak platform design. But when the main model is sound, extensibility is a good way to connect the platform to the rest of the operating model.
My preferred design approach
If I were designing this for a serious enterprise VCF platform, I would not start with approval policies. I would start with the platform boundaries.
The first step would be to define the basic consumption model: organizations, regions, zones, and region quotas. That gives the platform a structure before users start consuming anything.
After that, I would define the common landing zones and connectivity model. That means standard namespace classes, the VPC and connectivity model, projects, project roles, and the catalog items that represent the normal consumption paths.
Only then would I start adding policies. IaaS resource policies are useful for hard technical constraints. Lease policies are useful for temporary workloads. Day-2 policies are useful for operational control. Approval policies should be added where human approval actually adds value, not as the default answer to every governance question.
Finally, I would use extensibility for the things that need to connect to the rest of the organization, such as external validation, CMDB updates, ticketing, metadata, or approval enrichment.
This order matters because it changes the role of approvals. If you start with approvals, you risk building a ticketing system with a cloud portal in front of it. If you start with the platform boundaries, approvals become the exception rather than the foundation.
Closing thoughts
VCF Automation guardrails are not only about stopping users from doing things. They are mainly about making the platform easier to consume safely.
A good guardrail should not feel like unnecessary friction. It should make the intended path clearer, reduce the number of decisions an application team needs to make, protect the platform from uncontrolled growth, and make operations more predictable.
In older infrastructure designs, a lot of this discipline lived in documents, meetings, naming standards, and the heads of a few experienced engineers. That can work for a while, but it does not scale very well once more teams start consuming the platform.
What I like about the VCF Automation model is that more of this discipline can be encoded into the platform itself. Not everything, and not perfectly, but enough to make the operating model more explicit.
That is why guardrails are interesting to me. Not because they make self-service more restrictive, but because they make self-service more usable. Without them, a private cloud easily becomes just another shared infrastructure environment with a portal in front of it.

Leave a comment