When it comes to creating a design for NSX-T Multisite, use case and geography are two key factors.
Two common use cases for organizations to start looking at a multisite architecture are:
- Disaster Recovery – Protection against site failure.
- Availability – Workload pooling with active workloads at each site facilitating higher service availability.
Site geography from an NSX-T Multisite perspective divides multisite environments into two categories:
- Metropolitan region (<10 ms between any two sites)
- Large distance region (<150 ms between any two sites)
Together these variables give us four NSX-T Multisite scenarios to work with. All of them come with their own prerequisites, requirements, and capabilities.
In this article and the next I’m going to have a closer look at NSX-T Multisite in a “large distance – disaster recovery” scenario. Probably not the most common scenario and technically a bit more challenging which makes it all the more interesting to write about of course.
In this first part we focus on deploying and configuring the various NSX-T components for the multisite scenario. In part two we will look at what happens and needs to be done when a site failure occurs.
So where do we begin? With a picture of course!
The environment
The diagram below shows the starting point of our NSX-T Multisite journey:
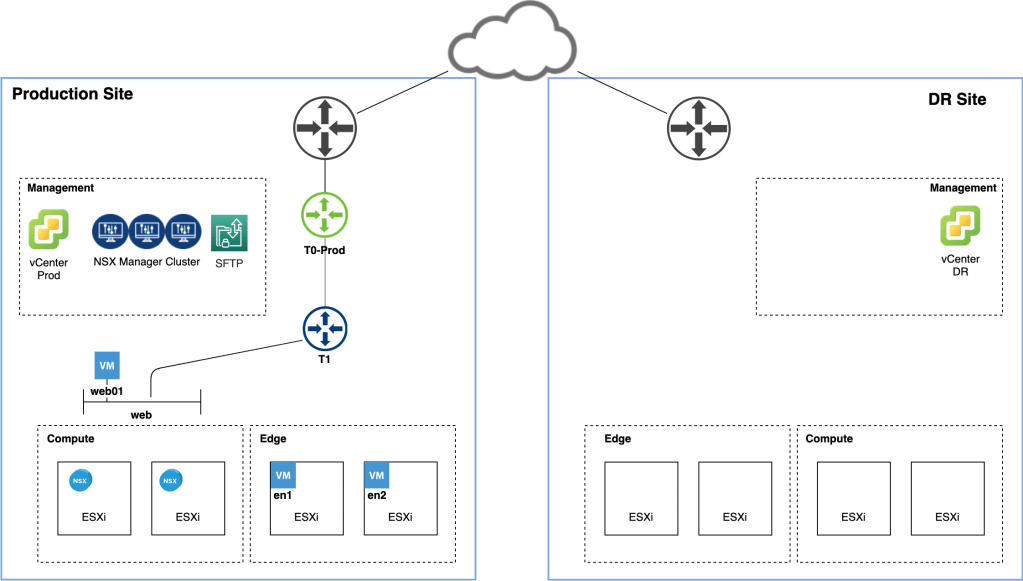
We have a production site where NSX-T 2.5.1 has been deployed. Workloads in the vSphere 6.7 U3 Compute cluster are connected to NSX-T segments behind a Tier-1 Gateway. The NSX-T Edge transport nodes are hosted in a dedicated vSphere cluster and a separate Management cluster hosts vCenter, NSX Manager, and a SFTP backup target.
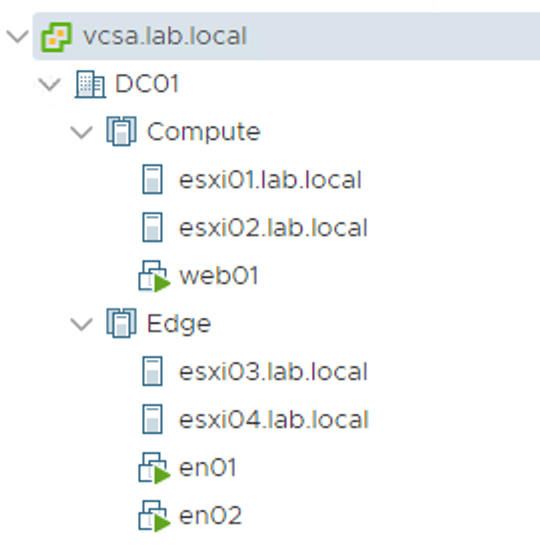
A second, identically equipped, disaster recovery site was recently put into operation. vSphere has just been installed and we’re now ready to configure NSX-T to leverage the new site redundancy.
Enable DNS
By default NSX-T transport nodes access the manager/controller nodes on their IP address. It is possible to change this behaviour so that FQDN is used instead.
Using DNS instead of IP address might or might not be a good practice, but for our NSX-T Multisite scenario it is a requirement.
Before enabling FQDN based access make sure that forward and reverse DNS records for the NSX Manager nodes and optionally the Manager cluster VIP are in place. Preferably these DNS records have a low TTL like 5 minutes or less.
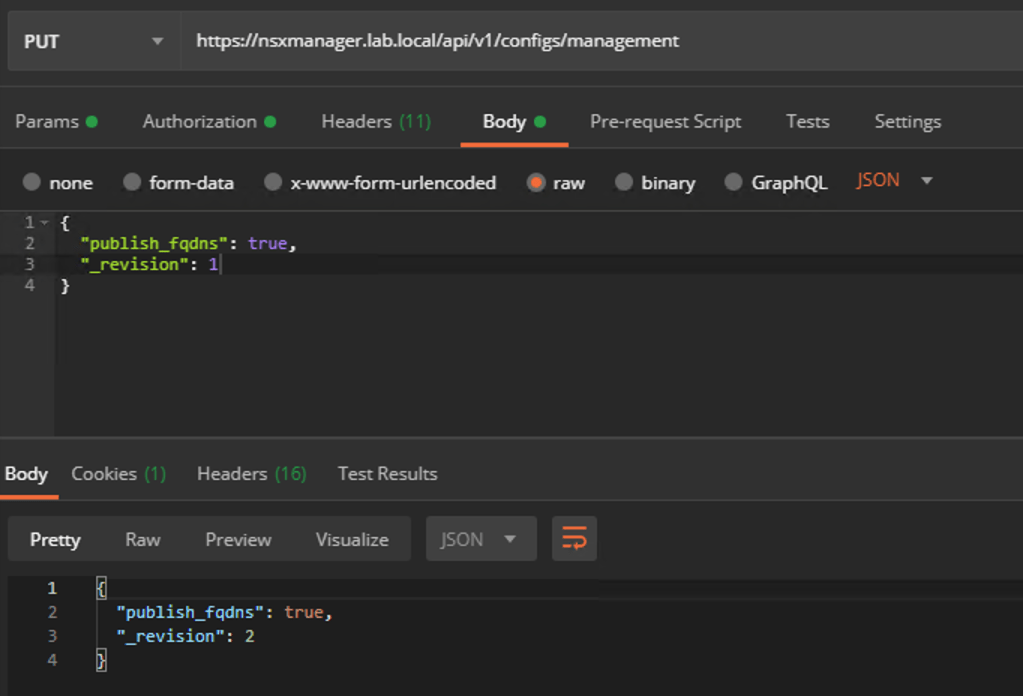
Enable FQDN with the following API call:
PUT https://<nsx-mgr>/api/v1/configs/management
With the request body containing the following piece of JSON code:
{
"publish_fqdns": true,
"_revision": 0
}
To verify that the transport nodes are successfully accessing the Manager/Controller nodes by FQDN, run the get controllers NSXCLI command from any transport node and check that the FQDNs are shown in the Controller FQDN column:

You probably figured this one out already, but from now on the DNS service hosting these records is critical for NSX-T’s wellbeing and we need to think about its availability. Hosting the DNS service on a third site might be something to consider here.
SFTP backup target
We’re doing disaster recovery here and as part of the NSX Manager recovery we need to be able to restore from an NSX Manager backup. For this reason it’s a good idea to move the SFTP backup target out of the production site. We could relocate it to a third site or to the DR site. Here I’m moving the SFTP server to the DR site:

After moving the SFTP backup target we should verify that backup is still working. We don’t want any surprises here:
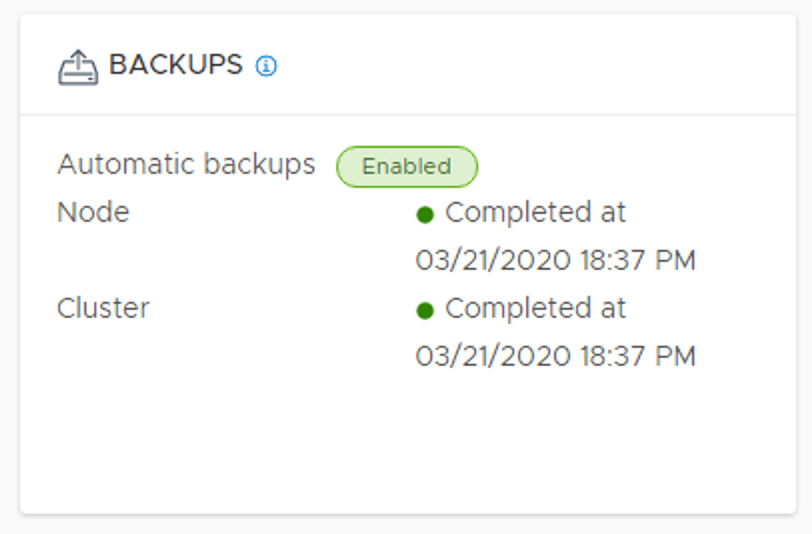
We also need to make sure that Detect NSX configuration change is enabled under the backup schedule:

Enabling this setting effectively enables continuous backup to the third/DR site.
NSX Manager node
As mentioned before, when the production site goes down, the NSX Manager cluster will be restored on the DR site. The restore operation requires a new NSX Manager node.
To save valuable time in a possibly stressful DR situation, we will deploy this NSX Manager node in advance using the NSX Manager OVF:
The base configuration that is done during the OVF deployment is sufficient for now. It’s just a restore target after all. We do want to document the node’s IP address because we need it when updating DNS.
One other thing we can do to save even more time is to configure the SFTP server settings. We do this from the new NSX Manager’s UI under System > Lifecycle Management > Backup & Restore > Restore:

That’s one less thing to worry about.
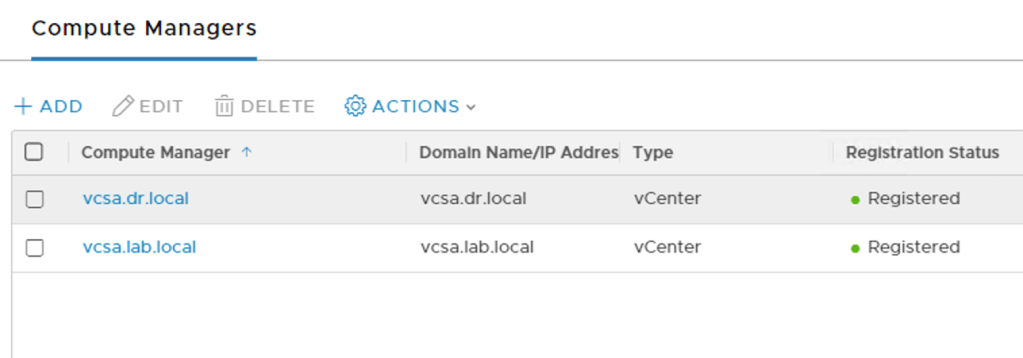
Compute Manager
Back at the production site it’s time to add the DR site’s vCenter instance as a Compute Manager to NSX Manager:
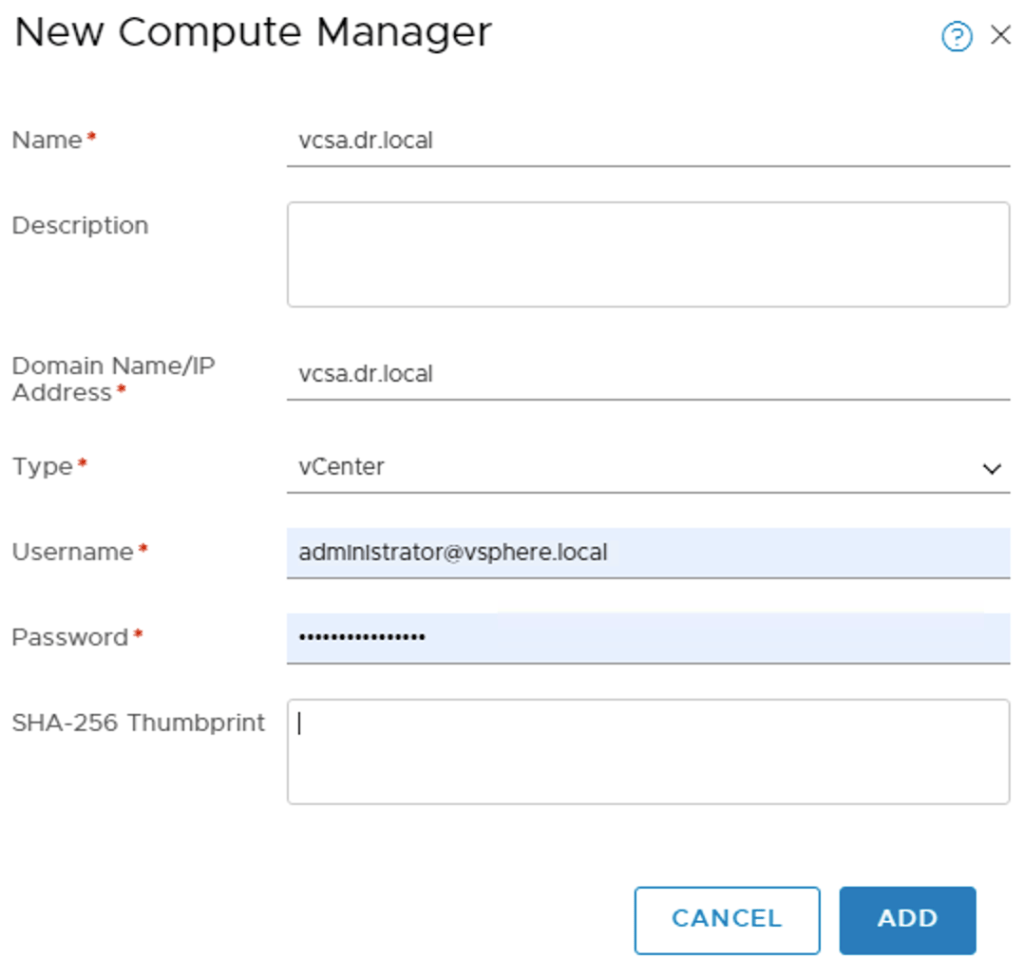
NSX Manager having access to the DR site’s vSphere environment makes it easier to deploy, configure, and manage transport nodes during normal circumstances.
Configure ESXi transport nodes
The ESXi hosts at the DR site will be incorporated into NSX-T by configuring them as transport nodes. This is done the ordinary way and might involve creating an uplink profile, transport node profile, and IP pool to match the specifics of the DR site:
Deploy Edge transport nodes
Just like the production site the DR site will have its own Tier-0 Gateway fuelled by two Edge transport nodes. Deploying these Edge transport nodes might also involve creating an uplink profile (when VLAN IDs for the transport VLAN do not match between the sites for example):

The new Edge nodes at the DR site are then added to their own NSX-T Edge Cluster:

Tier-0 Gateway
And here comes the Tier-0 Gateway with its external interfaces and routing configuration so that communication between NSX-T and the physical network at the DR site is possible:

Make sure to select the Edge Cluster belonging to the DR site.
Review
Time for another look at the diagram now that we’ve deployed and configured the NSX-T components at the DR site:
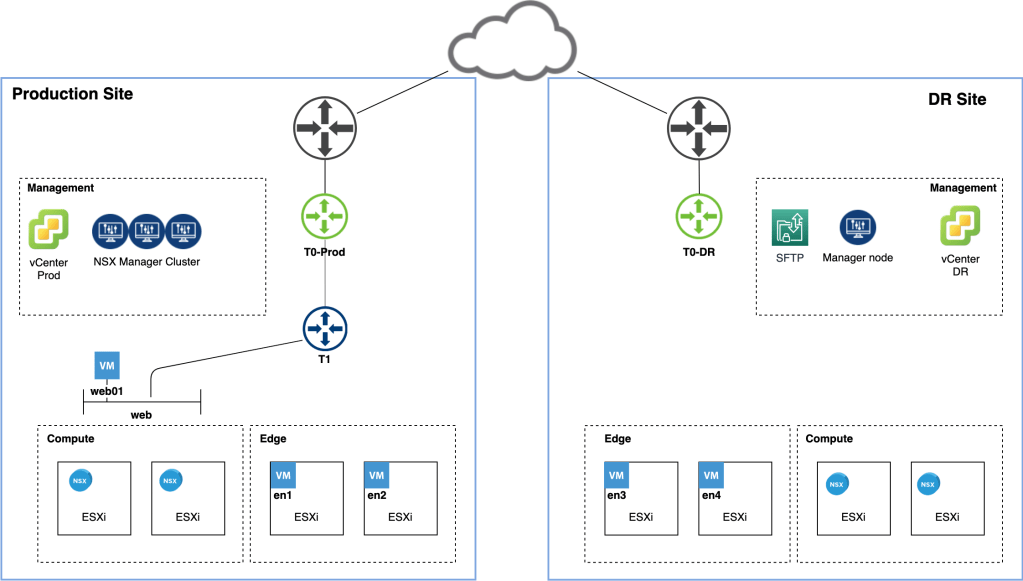
From an NSX-T perspective the DR site is now fully incorporated. In other words the transport nodes and logical network constructs of both sites are managed by the same NSX Manager cluster.
Summary
This completes part one of the series. We prepared NSX-T for site failover by making some configuration changes and deploying the necessary NSX-T components at the DR site. A quick summary of what we’ve done:
- Enabled FQDN so that transport nodes to use DNS instead of IP when accessing the central management/control plane.
- Moved the SFTP backup target to the DR site.
- Deployed an “empty” NSX Manager node at the DR site.
- Added vCenter DR as a compute manager to NSX Manager.
- Configured and deployed NSX-T transport nodes at the DR site.
- Configured a Tier-0 Gateway at the DR site.
Not too bad! In part two we will continue our journey and dive into handling an actual production site failure. Stay tuned!

Leave a comment