With every new release of NSX-T interesting features are added to the platform. Take failure domain for example.
Introduced in version 2.5, failure domain adds another layer of protection for the centralized services running on Tier-1 Gateways. It basically facilitates a rack aware placement mechanism for the Tier-1 service router (SR) components.
In today’s article I’m going to do a simple failure domain proof of concept. I’ll walk through the configuration steps for setting up failure domain and verify its functionality.
The lab environment
For this exercise I installed a vSphere cluster consisting of four ESXi hosts divided over two racks. I’m calling these the Edge racks and made this very advanced diagram:
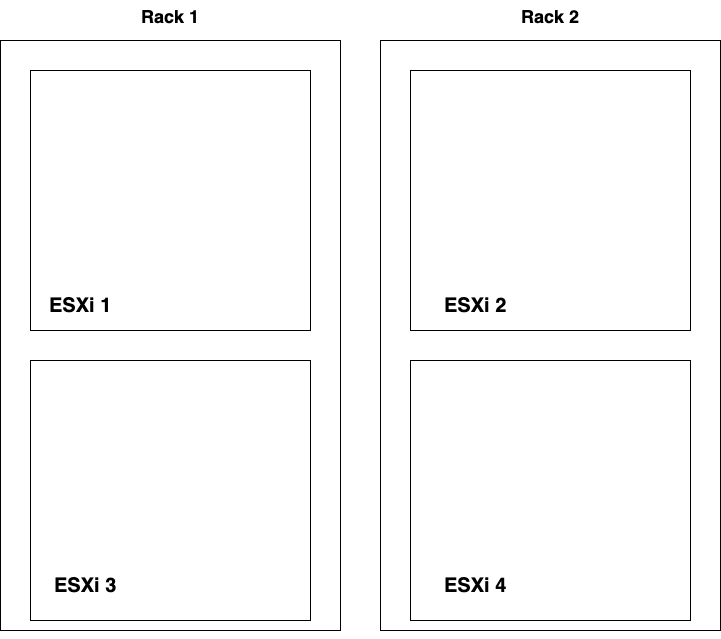
I then deployed four NSX-T Edge nodes (EN1 – EN4), one on each host, and added these to NSX-T Edge Cluster “T0 Cluster ECMP”:

I threw in a Tier-0 Gateway called “T0-01” which is running in Active-Active HA mode with ECMP enabled. The Tier-0’s 8 uplinks are all taking part in forwarding North-South traffic, simultaneously:
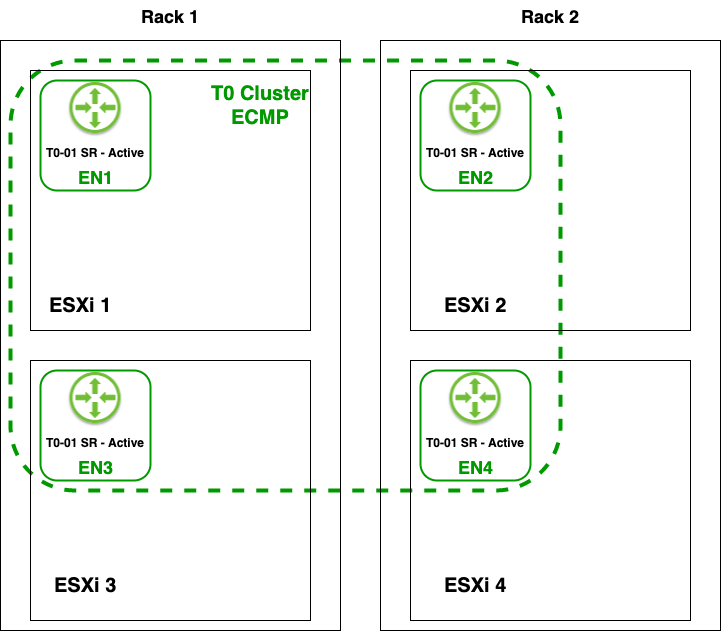
Finally, I deployed four more Edge nodes (EN5 – EN8), one on each host, and added these to Edge cluster “T1 Cluster”:
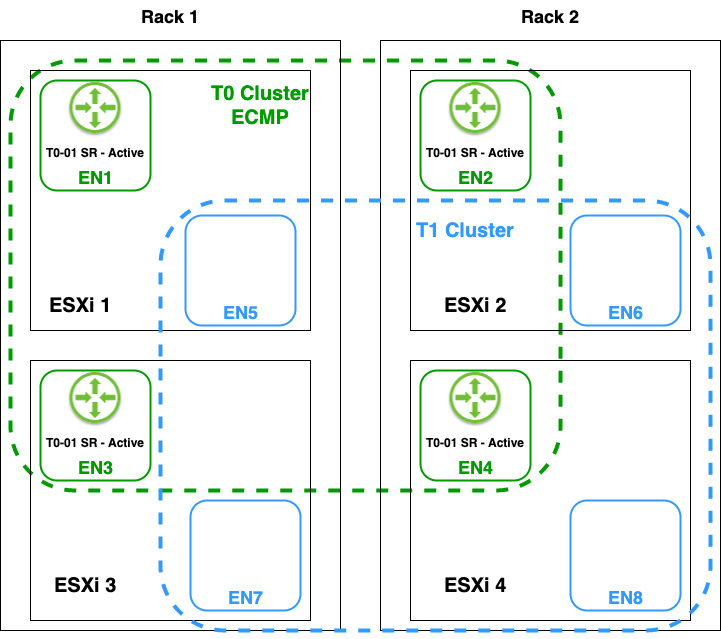
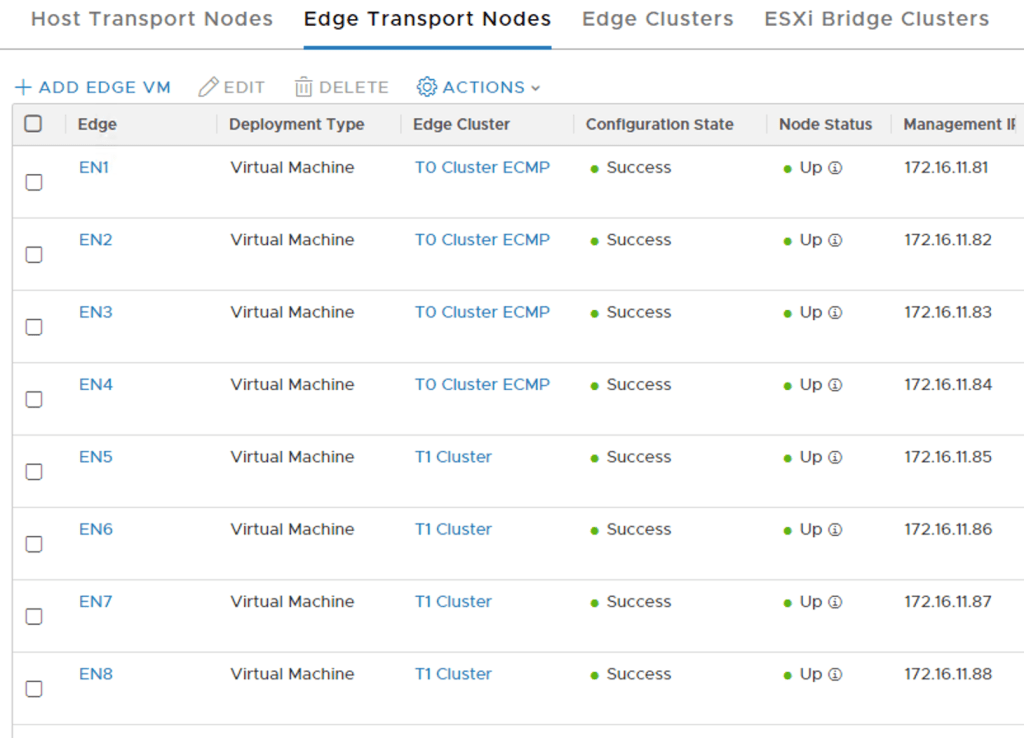
The eight Edge nodes in the NSX Manager UI:
Next step – Create Tier-1s
I will create Tier-1 Routers (Manager API) as opposed to Tier-1 Gateways (Policy API). This because the API call to trigger a Tier-1 SR reallocate I want to run later on only works on Tier-1 Routers. This has nothing to do with the failure domain feature itself which is compatible with both Tier-1 Routers and Tier-1 Gateways of course.
Configuring the first Tier-1 called “T1-01”:
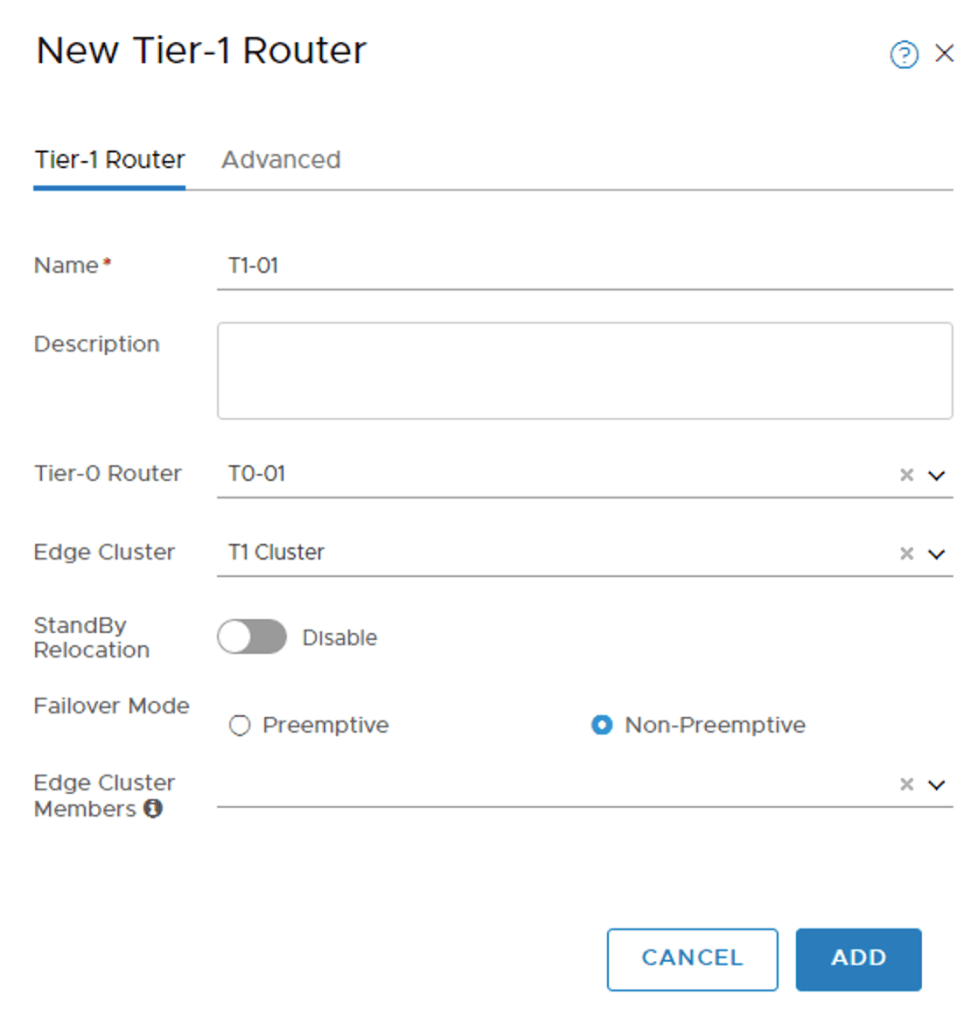
I’m selecting the “T1 Cluster” Edge Cluster and no specific Edge Cluster Members.
Both of the Tier-1s and the Tier-0 listed in the NSX Manager UI:
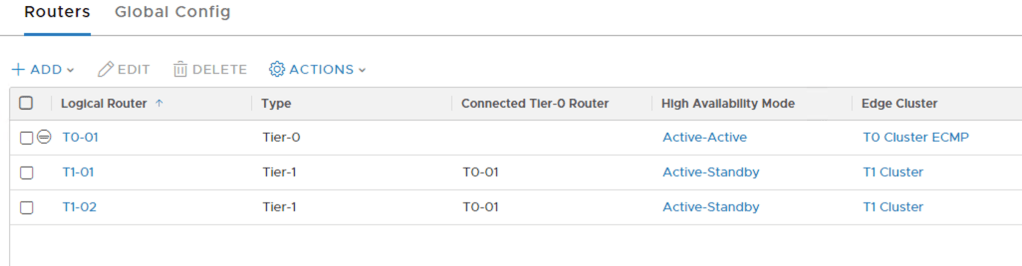
Tier-1 service routers
Selecting an Edge cluster for a Tier-1 indicates that you intend to run one or more centralized services on that Tier-1. This means that one active and one standby service router (SR) are instantiated on two different Edge nodes in that cluster (a Tier-1 SR always runs in Active-Standby HA mode).
By the way, you should not select an Edge Cluster for a Tier-1 if you don’t intend to run centralized services on it as this can lead to unintended hairpinning of traffic over the Edge nodes.
You noticed that I didn’t specify any Edge Cluster Members for the SRs. This results in the management plane picking them for me. So where did they end up?
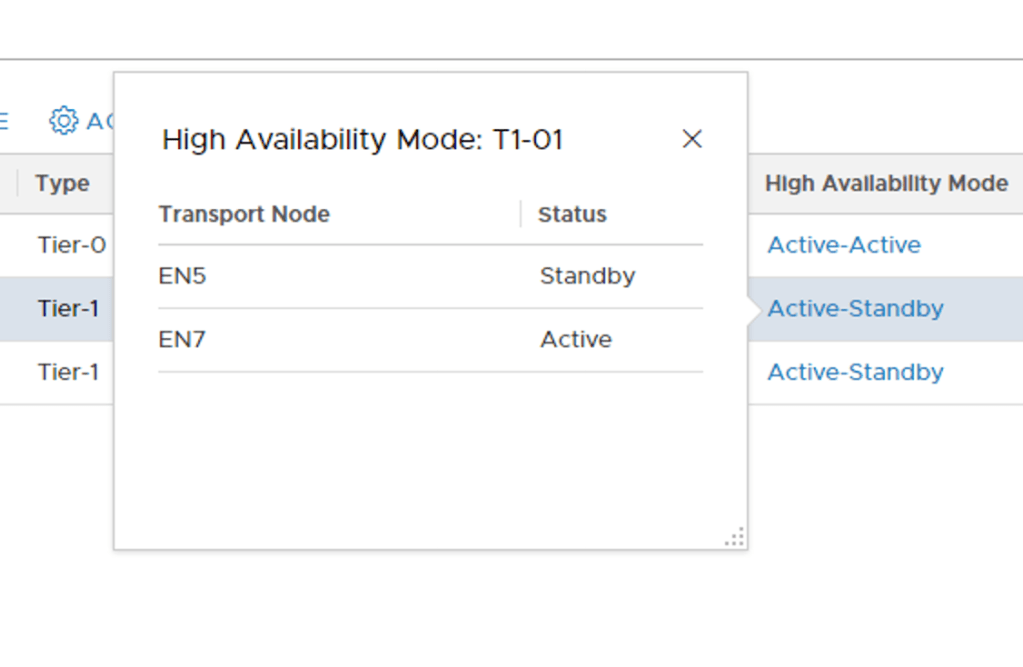
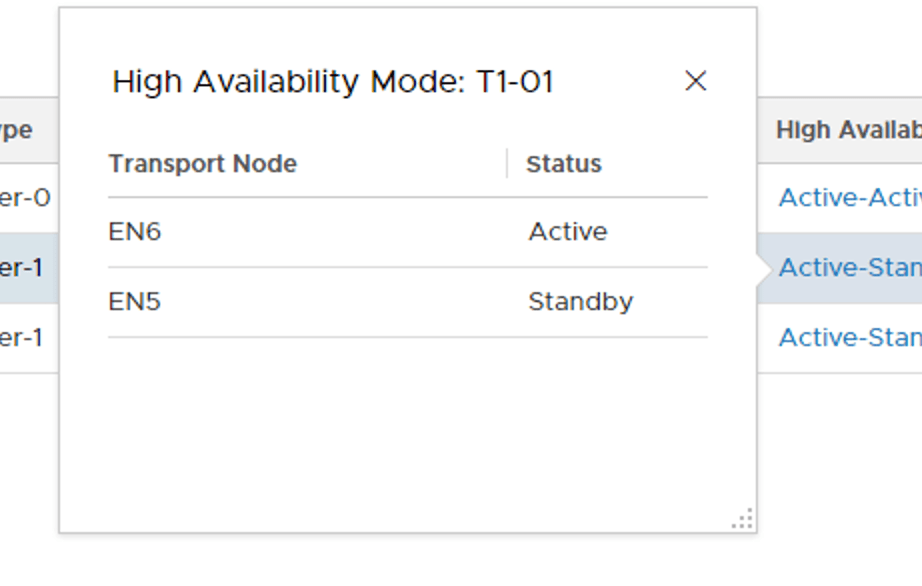
Clicking the Active-Standby link for each of the Tier-1 Routers reveals the SRs location. “T1-01” has its active SR on Edge node EN7 and its standby SR on Edge node EN5:
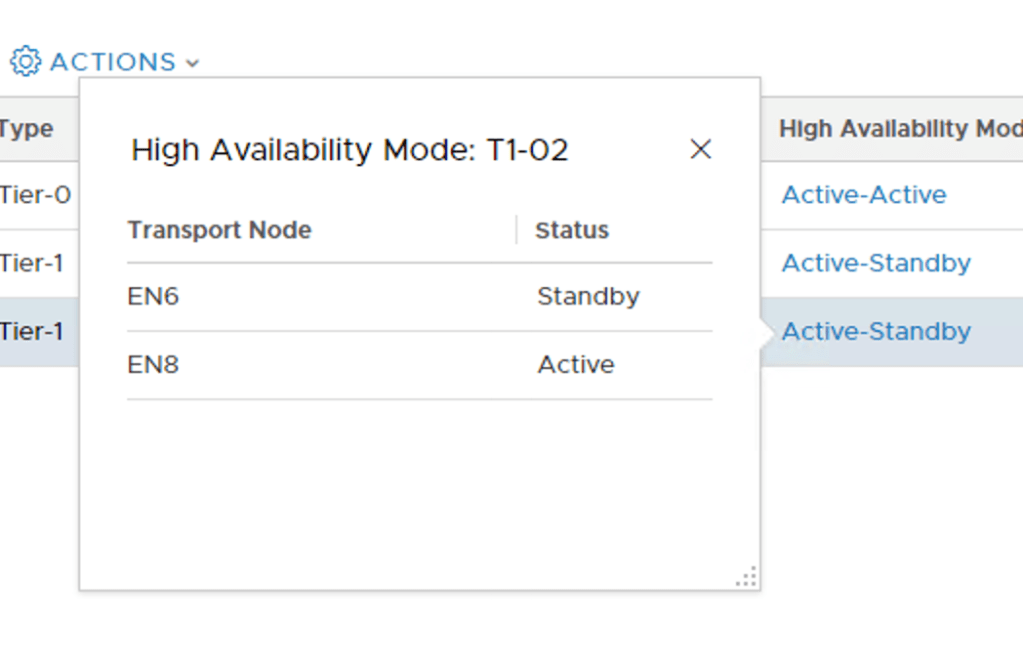
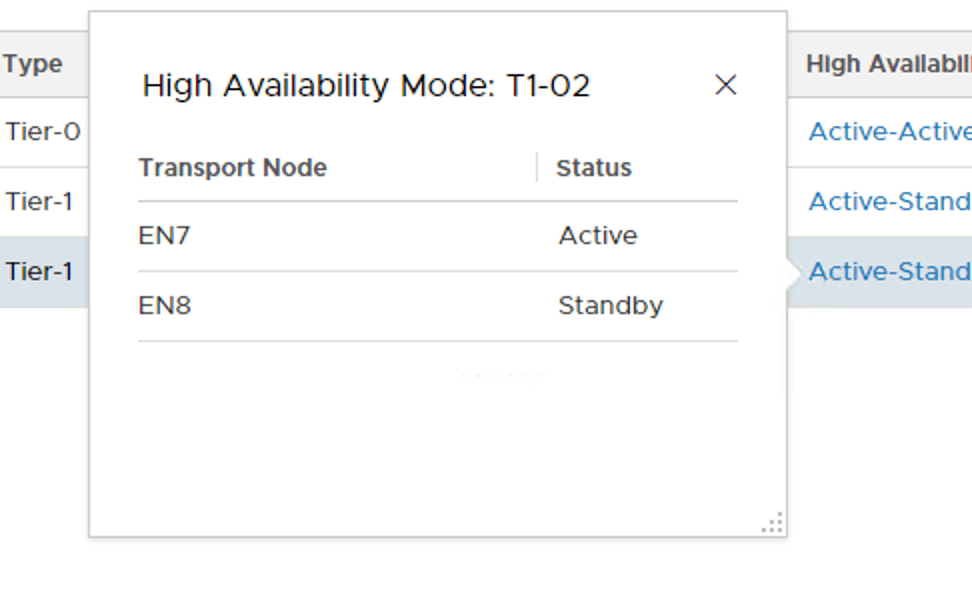
“T1-02” has its active SR on Edge node EN8 and its standby SR on Edge node EN6:
Fine. Let’s have a look at the Edge rack again now that we have introduced these Tier-1 SRs to the environment:

My two Tier-1s are in separate racks. Great! Or is it?
With the current Tier-1 SR placement a single Edge rack failure will result in one of the Tier-1 Routers losing both its active and the standby SR. That’s pretty bad.
Failure Domain
Failure domain prevents this silly SR placement from happening. Correctly configured, failure domain ensures that the active and standby SRs of a Tier-1 are always placed in different racks.
Sounds great. Time set this up.
Step 1 – Create two failure domains
Failure domains are created using a POST request to the NSX API at:
POST https://{{nsx-manager-fqdn}}/api/v1/failure-domains/
The request body for my first failure domain contains the following piece of JSON code:
{
"display_name": "Rack-1"
}
The JSON code for my second failure domain:
{
"display_name": "Rack-2"
}
Creating the first failure domain using Postman:
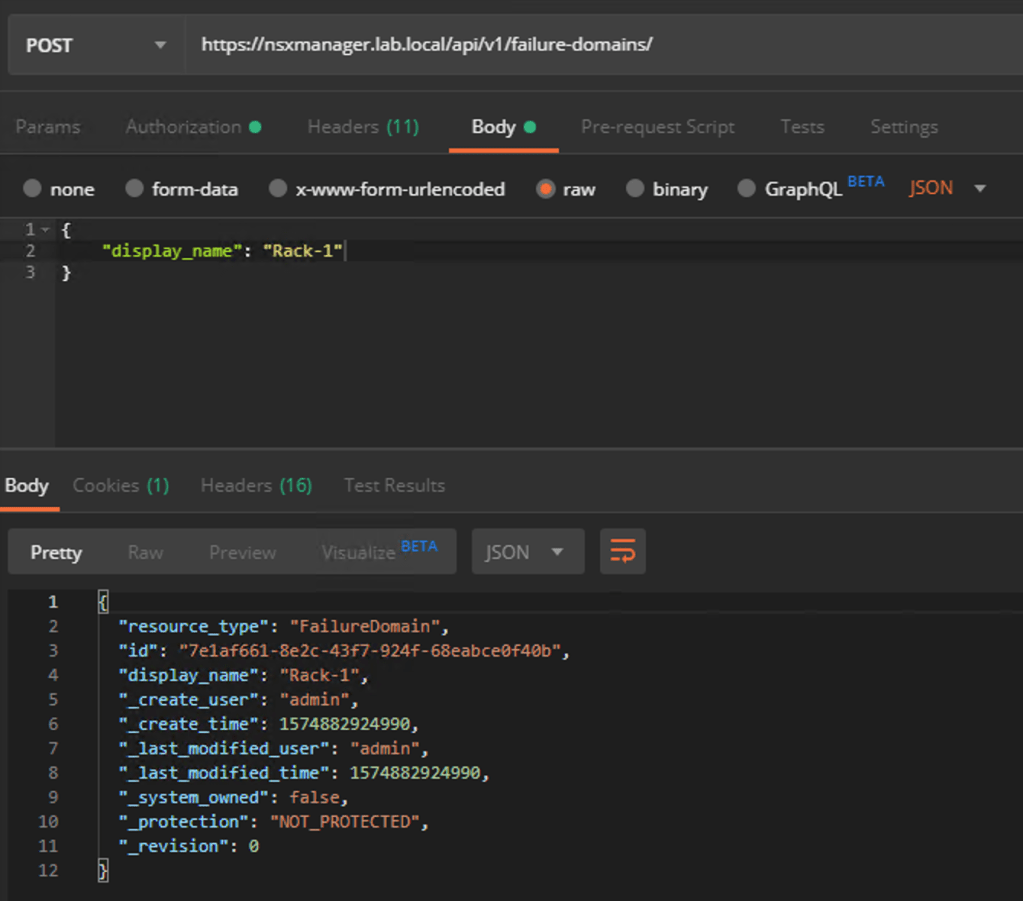
Copy the value for “id” from the request result for each of the failure domains as we need these in the next step.
Step 2 – Assign Edge nodes to failure domains
The Edge nodes in the “T1 Cluster” need to be assigned to their respective failure domains. This too is done through an API call to the Manager API.
For each Edge node we first retrieve its current configuration using the following GET request:
GET https://{{nsx-manager-fqdn}}/api/v1/transport-nodes/{{edge-node-id}}
You can find the ID of an Edge node in the NSX Manager UI (or via API):
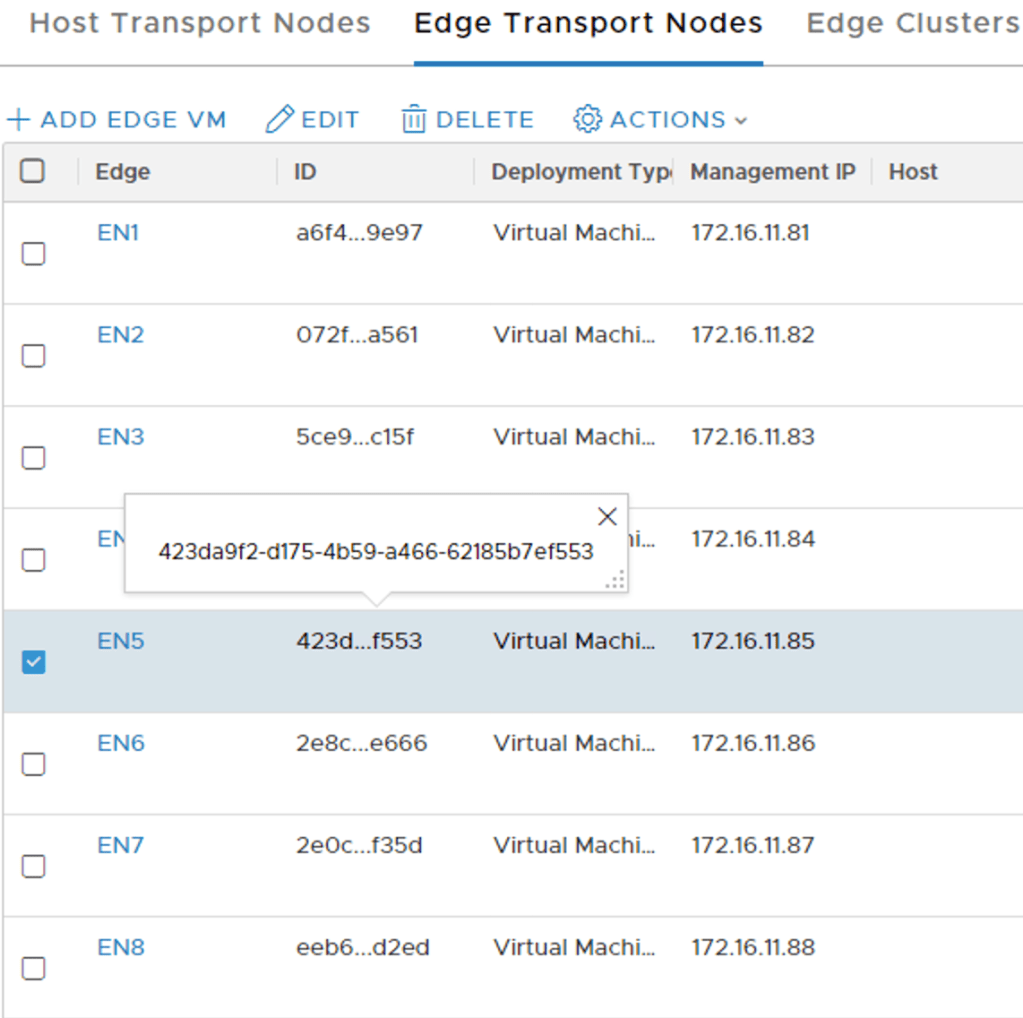
The GET request for Edge node EN5:
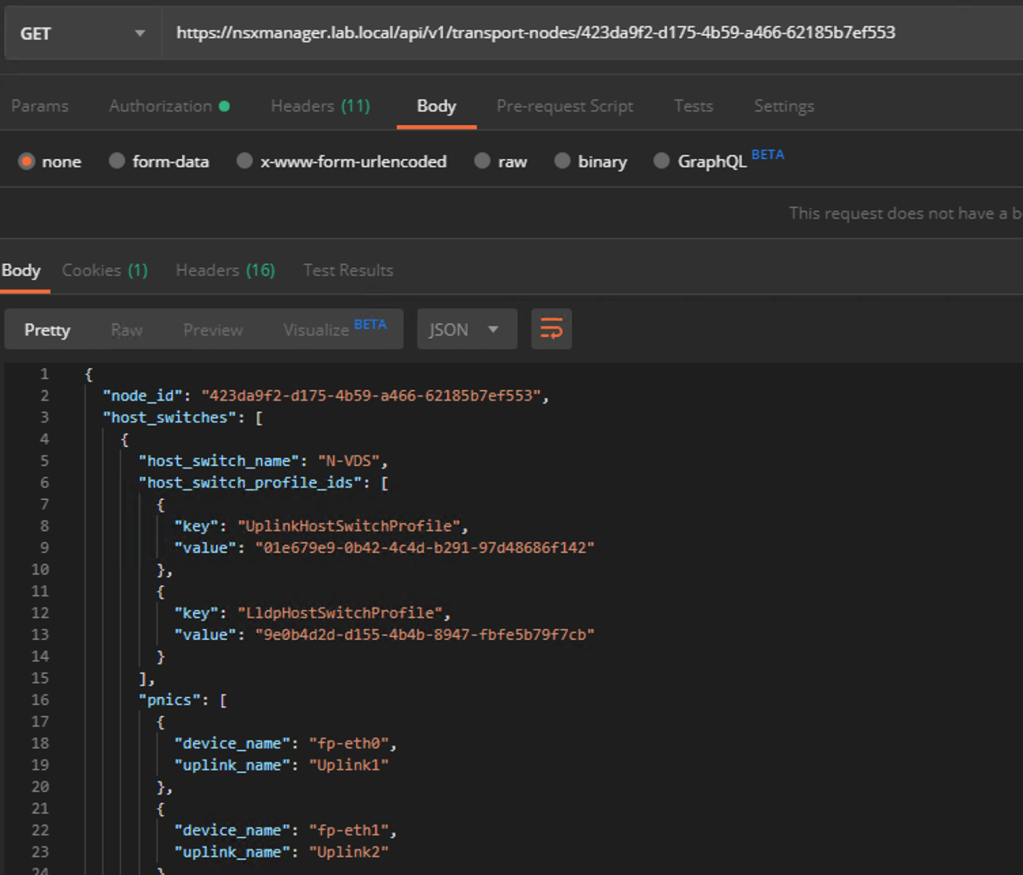
Copy the request result to the body of a new PUT request and change the value for “failure_domain_id” to match the ID of one of the newly created failure domains.
PUT https://{{nsx-manager-fqdn}}/api/v1/transport-nodes/{{edge-node-id}}
Which failure domain ID to use depends on the rack location of the Edge node. The following table lists the failure domain plan for my Tier-1 Edge nodes:
| Edge Node | Failure Domain | Failure Domain ID |
|---|---|---|
| EN5 | Rack-1 | 7e1af661-8e2c-43f7-924f-68eabce0f40b |
| EN6 | Rack-2 | d78707df-2f7f-48a9-9e3e-98a5523901c7 |
| EN7 | Rack-1 | 7e1af661-8e2c-43f7-924f-68eabce0f40b |
| EN8 | Rack-2 | d78707df-2f7f-48a9-9e3e-98a5523901c7 |
Four GET/PUT requests later the Edge nodes have been assigned to the correct failure domains.
Step 3 – Configure the Edge Cluster
The “T1 Cluster” Edge Cluster needs to be configured for failure domain based placement. This is also done via the API.
First a GET request to retrieve the current configuration of the Edge Cluster:
GET https://{{nsx-manager-fqdn}}/api/v1/edge-clusters/{{edge-cluster-id}}
The “edge-cluster-id” can be found in the NSX Manager UI (or via API):
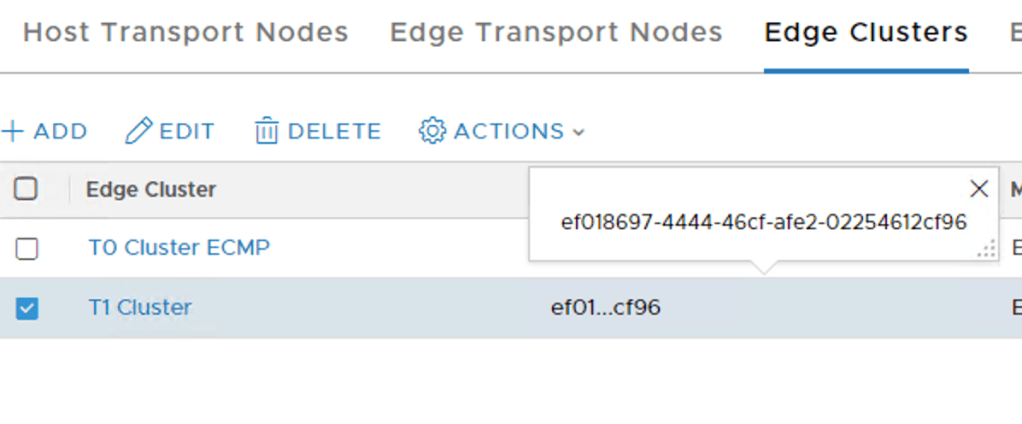
The GET request’s result in JSON:
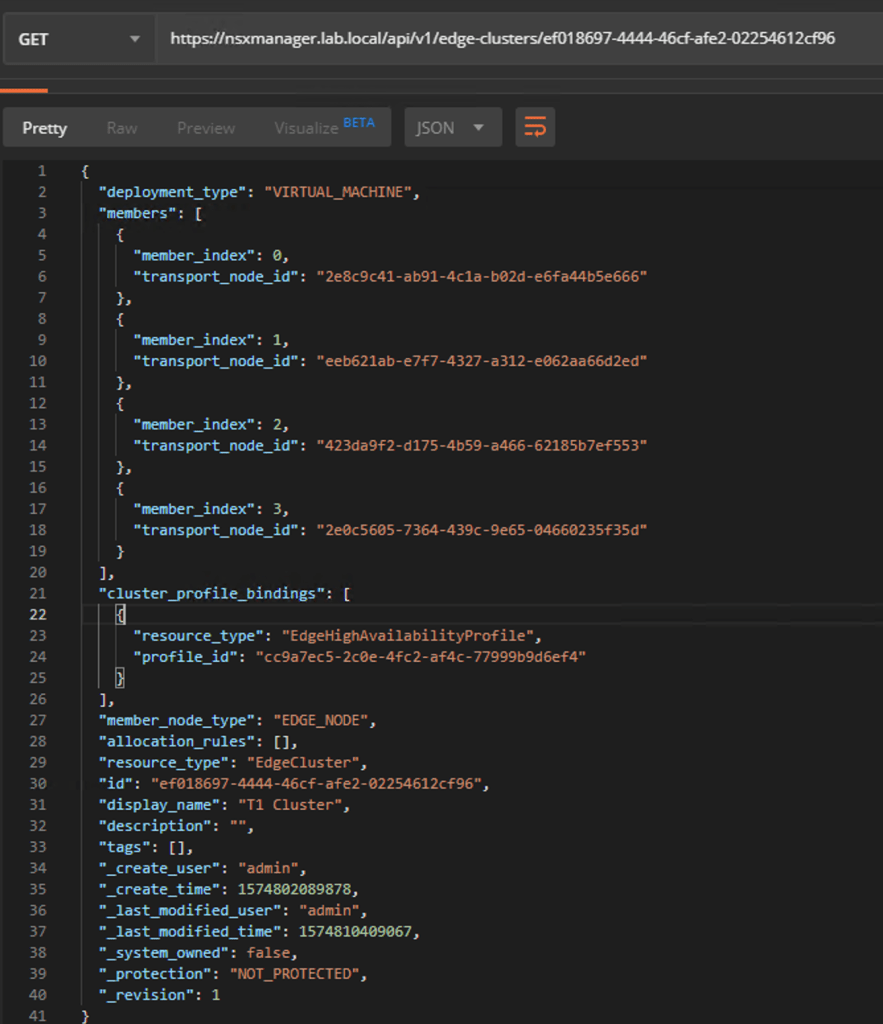
Again, you copy the request result to the body of a new PUT request. The only thing that we need to change here is the value for “allocation_rules”
from:
"allocation_rules": [],
to:
"allocation_rules": [ {"action": {"enabled": true,"action_type": "AllocationBasedOnFailureDomain" } } ],
Send the PUT request to:
PUT https://{{nsx-manager-fqdn}}/api/v1/edge-clusters/{{edge-cluster-id}}
And we’re done. From now on this Edge Cluster will perform failure domain based placement for new Tier-1 SRs.
A new Tier-1
Let’s put this to the test immediately by creating a new Tier-1.
Here comes “T1-03”:
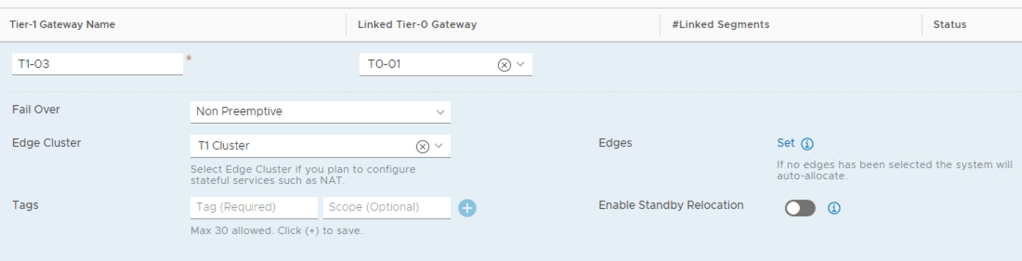
Once again I’m selecting the “T1 Cluster” Edge cluster and no specific Edge nodes (= Auto Allocated). So where did the management plane decide to place the SRs this time?

The Active SR is on EN5 and the standby SR on EN6. They indeed ended up in separate racks!
Existing Tier-1s
What about the Tier-1 SRs that were deployed before we configured failure domains? Can we trigger a reallocation so that they too are placed in accordance to the new failure domain configuration?
It turns out that we can, but it’s a data plane disruptive operation and, as far as I know, only works for Tier-1s created through the manager API (or in the UI under Advanced Networking & Security). Thank you Gary Hills for letting us know that the reallocate API call works for Tier-1s created in Policy UI/API as well by adding a header to the below request with key “X-Allow-Overwrite” and value of “true”:
A POST request on each of the existing Tier-1s will do the trick:
POST https://{{nsx-manager-fqdn}}/api/v1/logical-routers/{{logical-router-id}}?action=reallocate
The request body should contain the following JSON:
{
"edge_cluster_id": "{{edge-cluster-id}}"
}
The values for “logical-router-id” and “edge-cluster-id” can be found in the NSX Manager UI (or via API).
Request accepted by the API:
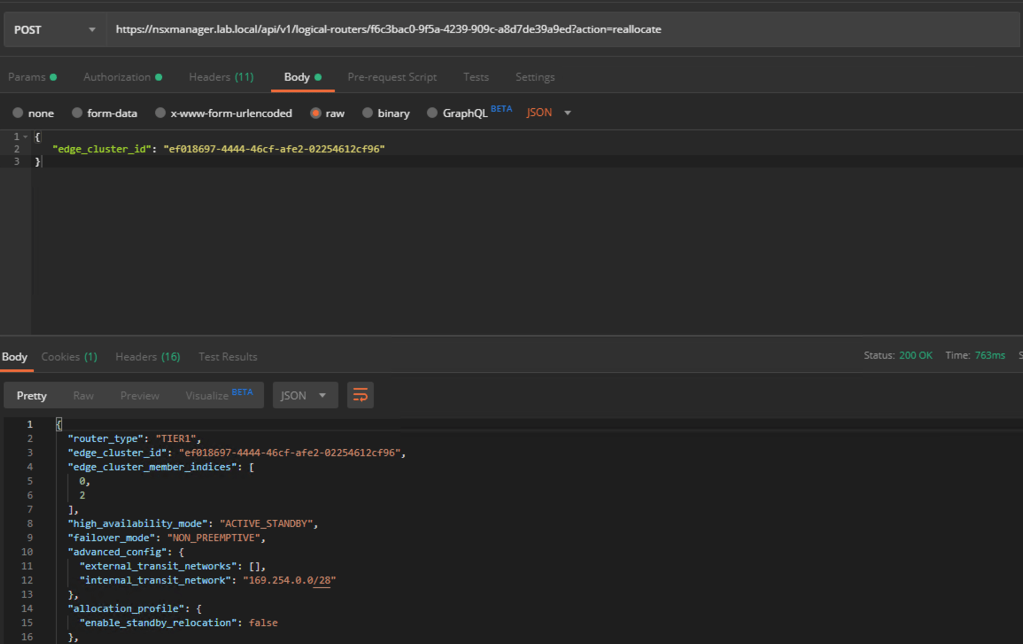
A reallocation process now takes places behind the scenes. A few moments later we see that the active and standby SRs of the existing Tier-1s are now in separate racks:
Let’s have a last look at the Edge rack after implementation and enforcement of the failure domains:

Looks so much better now!
Summary
Today we had a look at how to set up Tier-1 failure domain in NSX-T 2.5. The goal was to ensure that active and standby Tier-1 SRs ended up in separate racks.
Failure domain is a pretty cool and useful new feature adding extra protection for the Tier-1 SRs. Currently configurable via the API only, but that process was straight forward. With just a couple of request we got failure domains up and running.
Whether Tier-1 failure domain makes sense in your environment will depend on your NSX Edge design, number of Edge nodes, and things like future growth.
Good luck!
